 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient stereo matching on embedded GPUs with zero-means cross correlation
Dec 01, 2022


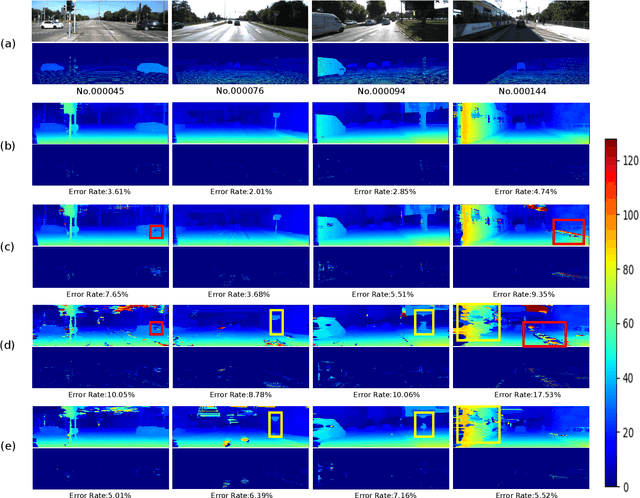
Mobile stereo-matching systems have become an important part of many applications, such as automated-driving vehicles and autonomous robots. Accurate stereo-matching methods usually lead to high computational complexity; however, mobile platforms have only limited hardware resources to keep their power consumption low; this makes it difficult to maintain both an acceptable processing speed and accuracy on mobile platforms. To resolve this trade-off, we herein propose a novel acceleration approach for the well-known zero-means normalized cross correlation (ZNCC) matching cost calculation algorithm on a Jetson Tx2 embedded GPU. In our method for accelerating ZNCC, target images are scanned in a zigzag fashion to efficiently reuse one pixel's computation for its neighboring pixels; this reduces the amount of data transmission and increases the utilization of on-chip registers, thus increasing the processing speed. As a result, our method is 2X faster than the traditional image scanning method, and 26% faster than the latest NCC method. By combining this technique with the domain transformation (DT) algorithm, our system show real-time processing speed of 32 fps, on a Jetson Tx2 GPU for 1,280x384 pixel images with a maximum disparity of 128. Additionally, the evaluation results on the KITTI 2015 benchmark show that our combined system is more accurate than the same algorithm combined with census by 7.26%, while maintaining almost the same processing speed.
Population structure-learned classifier for high-dimension low-sample-size class-imbalanced problem
Sep 10, 2020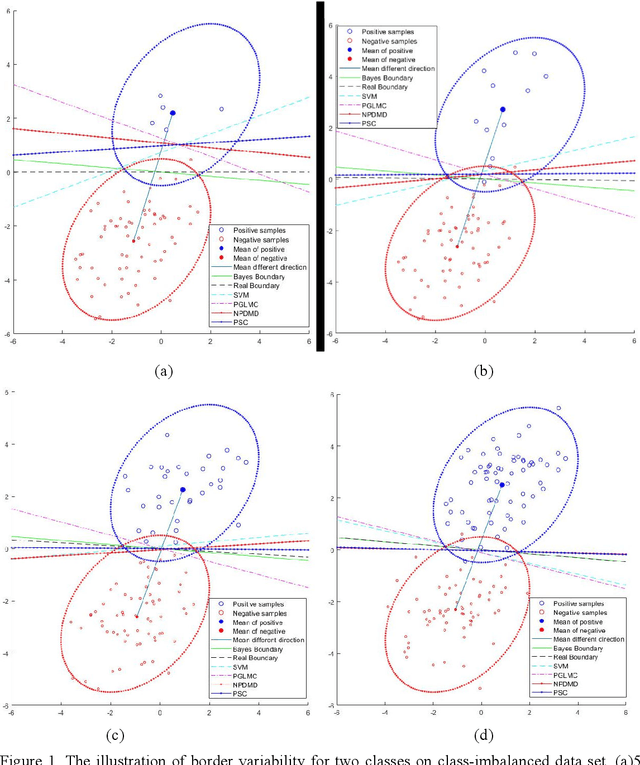
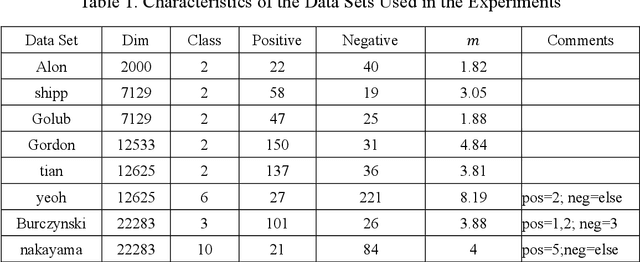
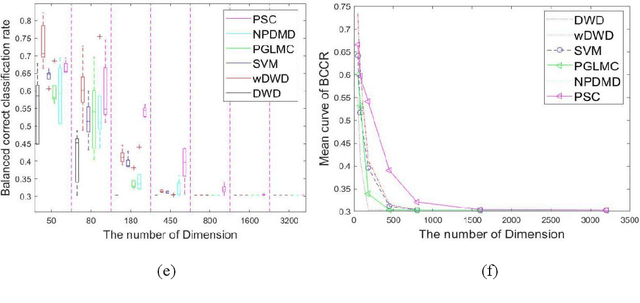

The Classification on high-dimension low-sample-size data (HDLSS) is a challenging problem and it is common to have class-imbalanced data in most application fields. We term this as Imbalanced HDLSS (IHDLSS). Recent theoretical results reveal that the classification criterion and tolerance similarity are crucial to HDLSS, which emphasizes the maximization of within-class variance on the premise of class separability. Based on this idea, a novel linear binary classifier, termed Population Structure-learned Classifier (PSC), is proposed. The proposed PSC can obtain better generalization performance on IHDLSS by maximizing the sum of inter-class scatter matrix and intra-class scatter matrix on the premise of class separability and assigning different intercept values to majority and minority classes. The salient features of the proposed approach are: (1) It works well on IHDLSS; (2) The inverse of high dimensional matrix can be solved in low dimensional space; (3) It is self-adaptive in determining the intercept term for each class; (4) It has the same computational complexity as the SVM. A series of evaluations are conducted on one simulated data set and eight real-world benchmark data sets on IHDLSS on gene analysis. Experimental results demonstrate that the PSC is superior to the state-of-art methods in IHDLSS.
Targeted Advertising Based on Browsing History
Nov 13, 2017

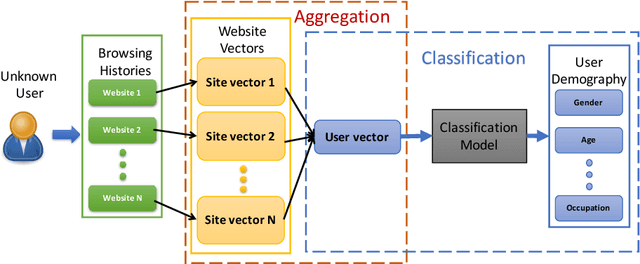
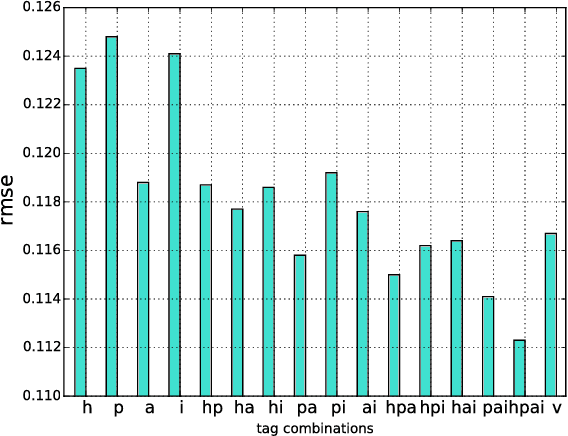
Audience interest, demography, purchase behavior and other possible classifications are ex- tremely important factors to be carefully studied in a targeting campaign. This information can help advertisers and publishers deliver advertisements to the right audience group. How- ever, it is not easy to collect such information, especially for the online audience with whom we have limited interaction and minimum deterministic knowledge. In this paper, we pro- pose a predictive framework that can estimate online audience demographic attributes based on their browsing histories. Under the proposed framework, first, we retrieve the content of the websites visited by audience, and represent the content as website feature vectors; second, we aggregate the vectors of websites that audience have visited and arrive at feature vectors representing the users; finally, the support vector machine is exploited to predict the audience demographic attributes. The key to achieving good prediction performance is preparing representative features of the audience. Word Embedding, a widely used tech- nique in natural language processing tasks, together with term frequency-inverse document frequency weighting scheme is used in the proposed method. This new representation ap- proach is unsupervised and very easy to implement. The experimental results demonstrate that the new audience feature representation method is more powerful than existing baseline methods, leading to a great improvement in prediction accuracy.
A Novel Progressive Learning Technique for Multi-class Classification
Jan 22, 2017
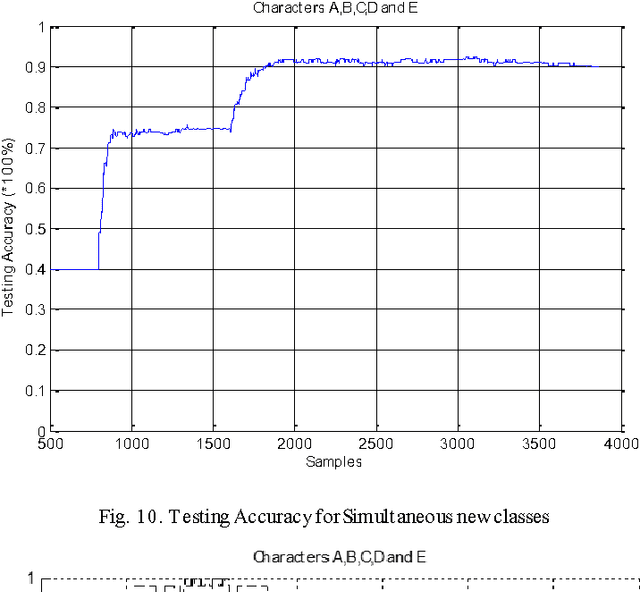

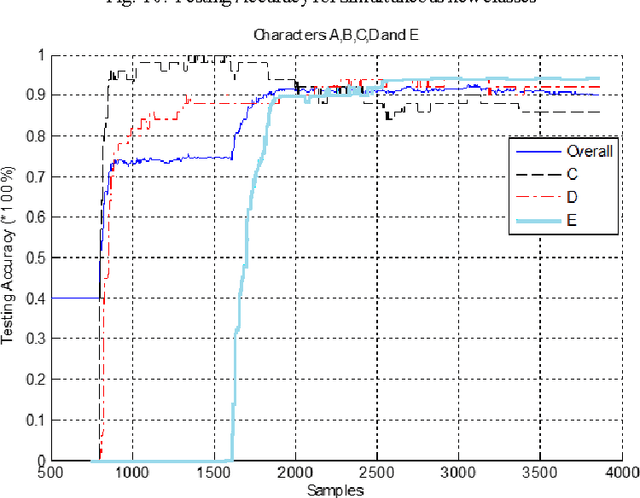
In this paper, a progressive learning technique for multi-class classification is proposed. This newly developed learning technique is independent of the number of class constraints and it can learn new classes while still retaining the knowledge of previous classes. Whenever a new class (non-native to the knowledge learnt thus far) is encountered, the neural network structure gets remodeled automatically by facilitating new neurons and interconnections, and the parameters are calculated in such a way that it retains the knowledge learnt thus far. This technique is suitable for real-world applications where the number of classes is often unknown and online learning from real-time data is required. The consistency and the complexity of the progressive learning technique are analyzed. Several standard datasets are used to evaluate the performance of the developed technique. A comparative study shows that the developed technique is superior.
A Novel Progressive Multi-label Classifier for Classincremental Data
Sep 23, 2016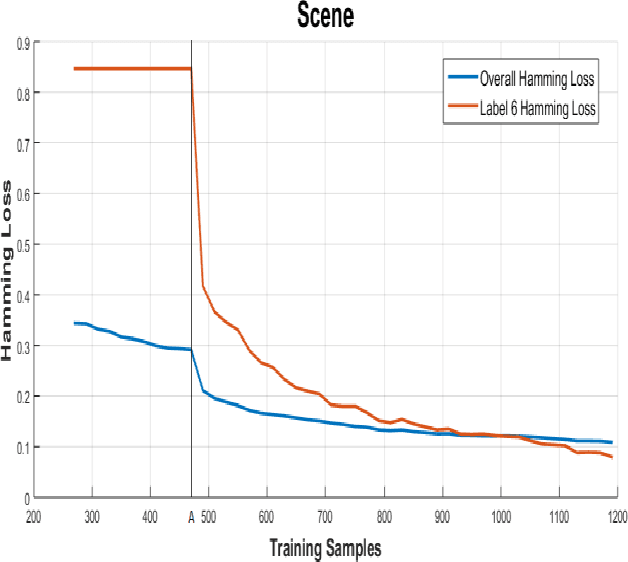
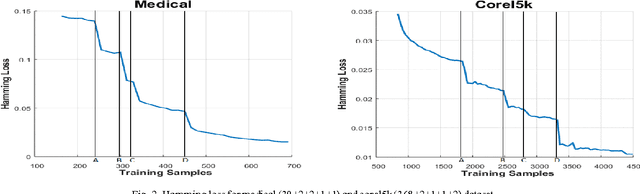
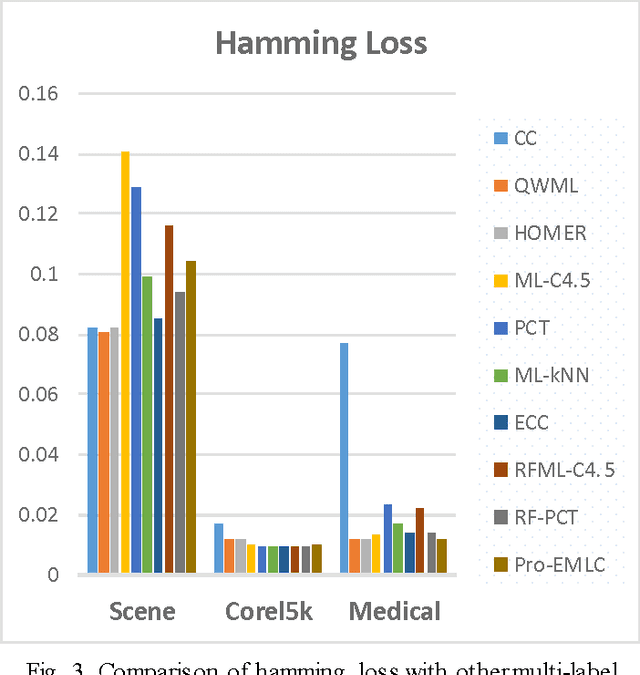
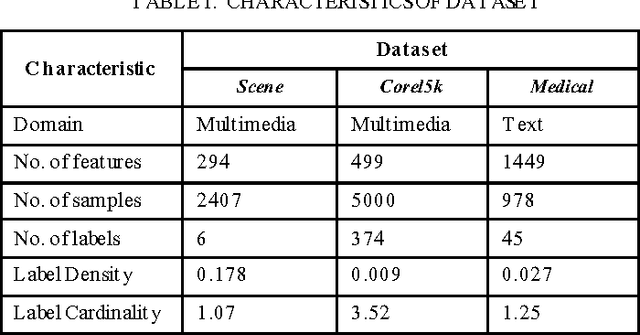
In this paper, a progressive learning algorithm for multi-label classification to learn new labels while retaining the knowledge of previous labels is designed. New output neurons corresponding to new labels are added and the neural network connections and parameters are automatically restructured as if the label has been introduced from the beginning. This work is the first of the kind in multi-label classifier for class-incremental learning. It is useful for real-world applications such as robotics where streaming data are available and the number of labels is often unknown. Based on the Extreme Learning Machine framework, a novel universal classifier with plug and play capabilities for progressive multi-label classification is developed. Experimental results on various benchmark synthetic and real datasets validate the efficiency and effectiveness of our proposed algorithm.
An Online Universal Classifier for Binary, Multi-class and Multi-label Classification
Sep 03, 2016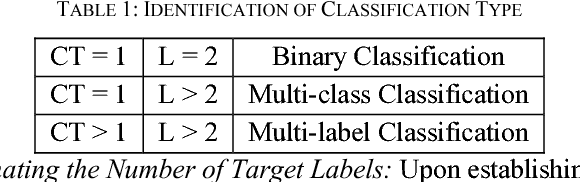
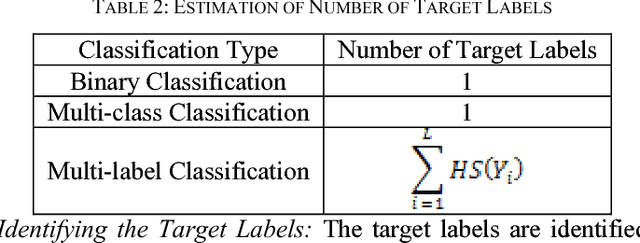


Classification involves the learning of the mapping function that associates input samples to corresponding target label. There are two major categories of classification problems: Single-label classification and Multi-label classification. Traditional binary and multi-class classifications are sub-categories of single-label classification. Several classifiers are developed for binary, multi-class and multi-label classification problems, but there are no classifiers available in the literature capable of performing all three types of classification. In this paper, a novel online universal classifier capable of performing all the three types of classification is proposed. Being a high speed online classifier, the proposed technique can be applied to streaming data applications. The performance of the developed classifier is evaluated using datasets from binary, multi-class and multi-label problems. The results obtained are compared with state-of-the-art techniques from each of the classification types.
A novel online multi-label classifier for high-speed streaming data applications
Sep 01, 2016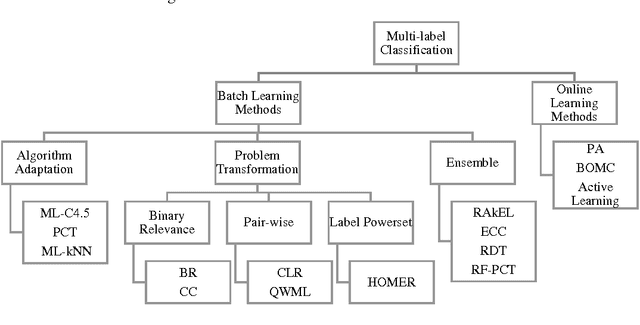
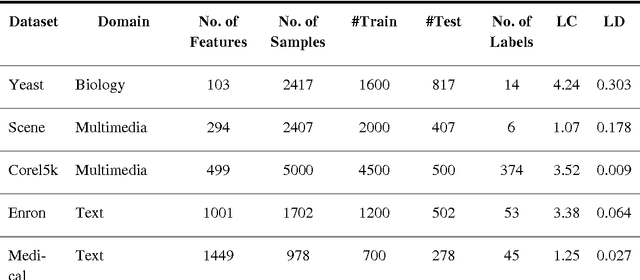
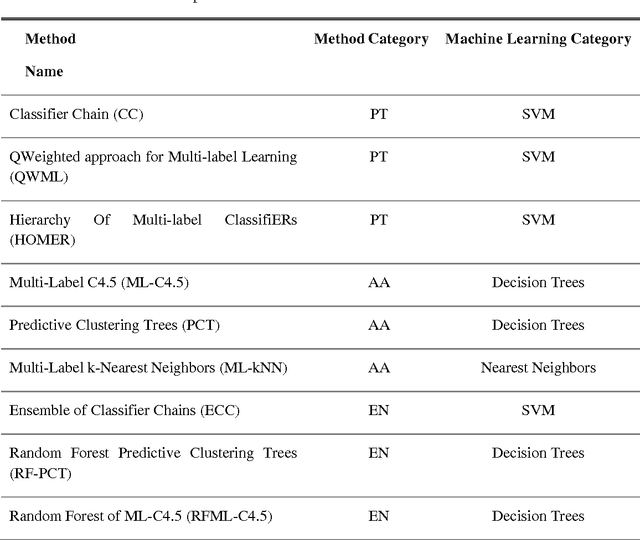
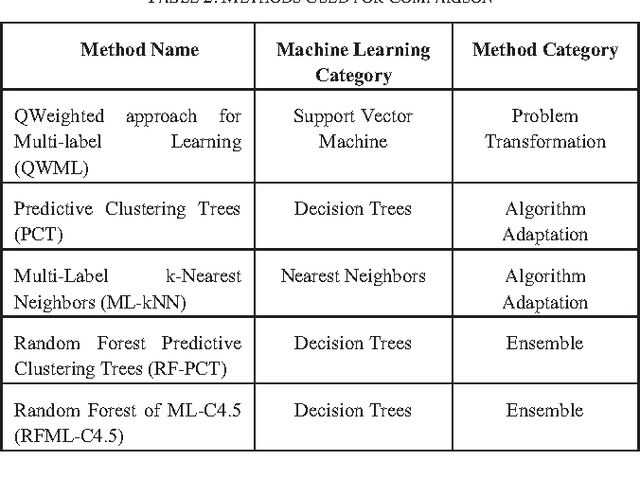
In this paper, a high-speed online neural network classifier based on extreme learning machines for multi-label classification is proposed. In multi-label classification, each of the input data sample belongs to one or more than one of the target labels. The traditional binary and multi-class classification where each sample belongs to only one target class forms the subset of multi-label classification. Multi-label classification problems are far more complex than binary and multi-class classification problems, as both the number of target labels and each of the target labels corresponding to each of the input samples are to be identified. The proposed work exploits the high-speed nature of the extreme learning machines to achieve real-time multi-label classification of streaming data. A new threshold-based online sequential learning algorithm is proposed for high speed and streaming data classification of multi-label problems. The proposed method is experimented with six different datasets from different application domains such as multimedia, text, and biology. The hamming loss, accuracy, training time and testing time of the proposed technique is compared with nine different state-of-the-art methods. Experimental studies shows that the proposed technique outperforms the existing multi-label classifiers in terms of performance and speed.
A Novel Online Real-time Classifier for Multi-label Data Streams
Aug 31, 2016

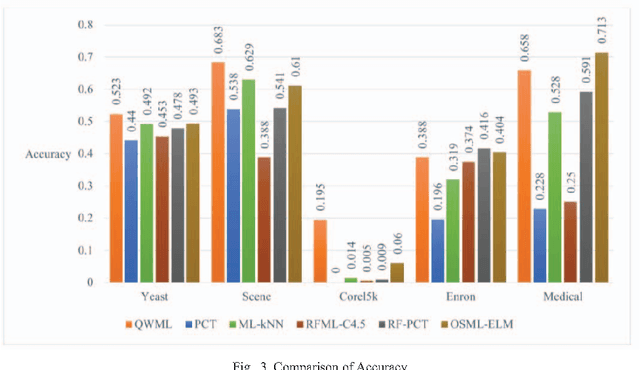
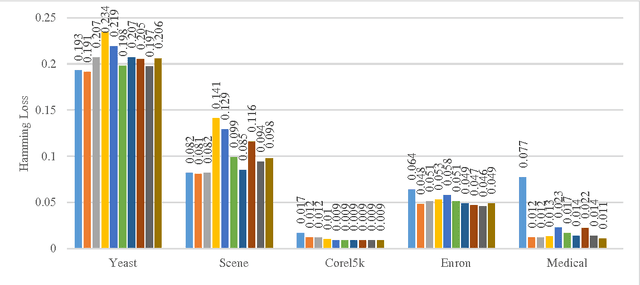
In this paper, a novel extreme learning machine based online multi-label classifier for real-time data streams is proposed. Multi-label classification is one of the actively researched machine learning paradigm that has gained much attention in the recent years due to its rapidly increasing real world applications. In contrast to traditional binary and multi-class classification, multi-label classification involves association of each of the input samples with a set of target labels simultaneously. There are no real-time online neural network based multi-label classifier available in the literature. In this paper, we exploit the inherent nature of high speed exhibited by the extreme learning machines to develop a novel online real-time classifier for multi-label data streams. The developed classifier is experimented with datasets from different application domains for consistency, performance and speed. The experimental studies show that the proposed method outperforms the existing state-of-the-art techniques in terms of speed and accuracy and can classify multi-label data streams in real-time.
A High Speed Multi-label Classifier based on Extreme Learning Machines
Aug 31, 2016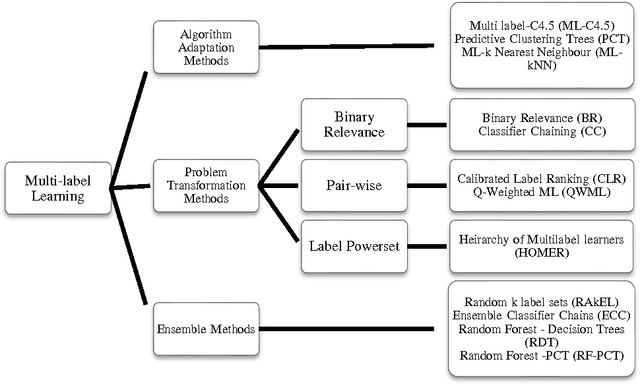
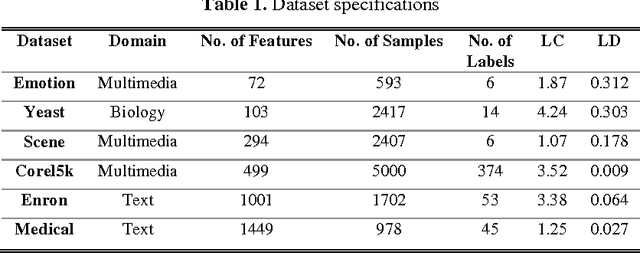
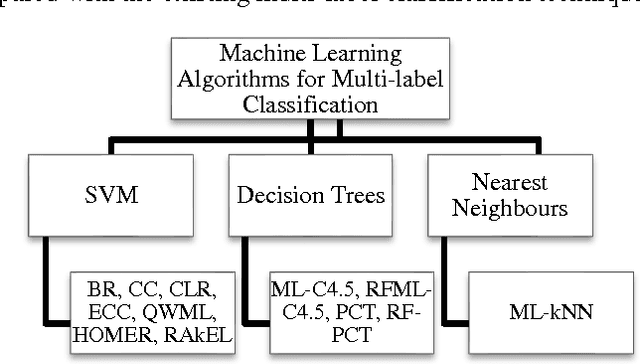
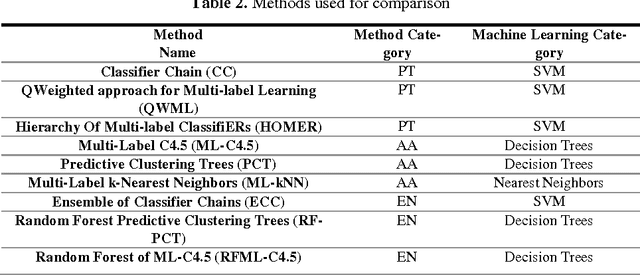
In this paper a high speed neural network classifier based on extreme learning machines for multi-label classification problem is proposed and dis-cussed. Multi-label classification is a superset of traditional binary and multi-class classification problems. The proposed work extends the extreme learning machine technique to adapt to the multi-label problems. As opposed to the single-label problem, both the number of labels the sample belongs to, and each of those target labels are to be identified for multi-label classification resulting in in-creased complexity. The proposed high speed multi-label classifier is applied to six benchmark datasets comprising of different application areas such as multi-media, text and biology. The training time and testing time of the classifier are compared with those of the state-of-the-arts methods. Experimental studies show that for all the six datasets, our proposed technique have faster execution speed and better performance, thereby outperforming all the existing multi-label clas-sification methods.
Multi-Label Classification Method Based on Extreme Learning Machines
Aug 30, 2016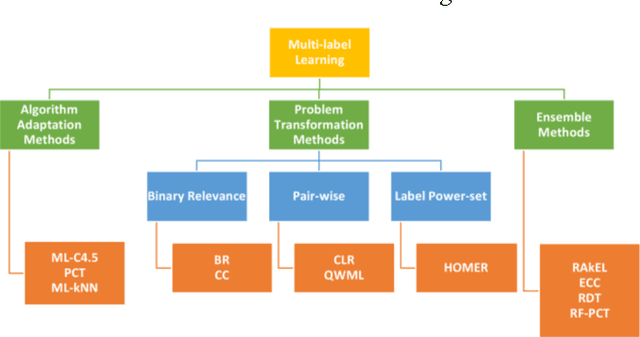
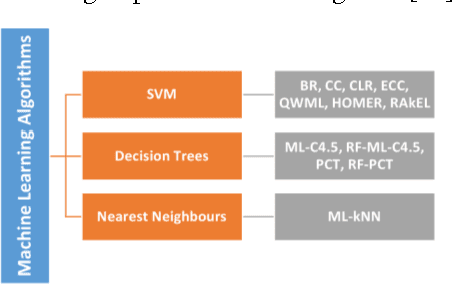
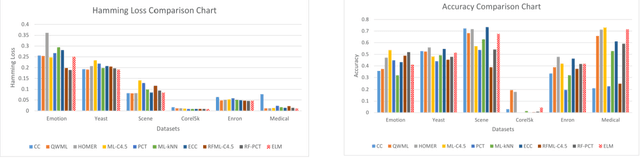
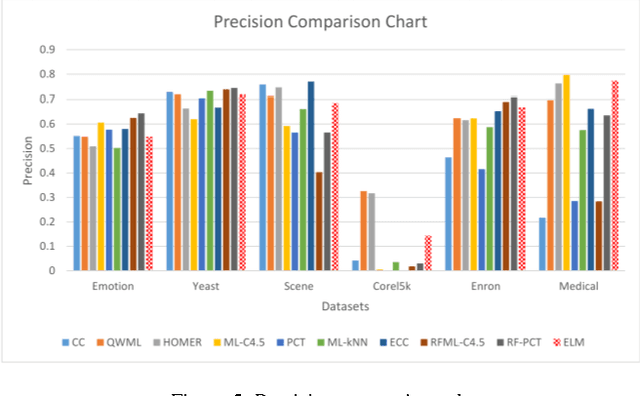
In this paper, an Extreme Learning Machine (ELM) based technique for Multi-label classification problems is proposed and discussed. In multi-label classification, each of the input data samples belongs to one or more than one class labels. The traditional binary and multi-class classification problems are the subset of the multi-label problem with the number of labels corresponding to each sample limited to one. The proposed ELM based multi-label classification technique is evaluated with six different benchmark multi-label datasets from different domains such as multimedia, text and biology. A detailed comparison of the results is made by comparing the proposed method with the results from nine state of the arts techniques for five different evaluation metrics. The nine methods are chosen from different categories of multi-label methods. The comparative results shows that the proposed Extreme Learning Machine based multi-label classification technique is a better alternative than the existing state of the art methods for multi-label problems.