 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Advertising Based on Browsing History
Nov 13, 2017

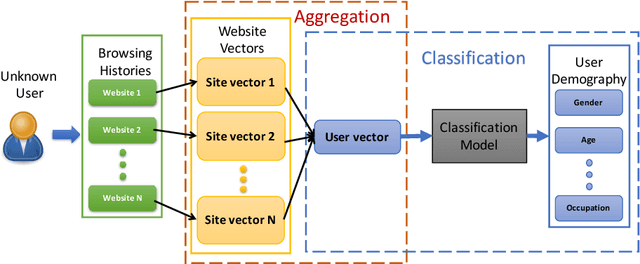
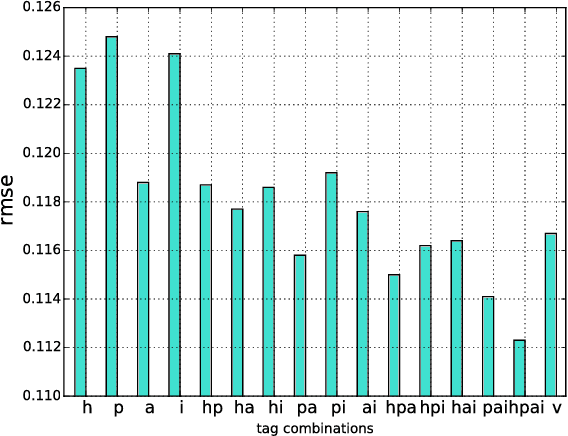
Audience interest, demography, purchase behavior and other possible classifications are ex- tremely important factors to be carefully studied in a targeting campaign. This information can help advertisers and publishers deliver advertisements to the right audience group. How- ever, it is not easy to collect such information, especially for the online audience with whom we have limited interaction and minimum deterministic knowledge. In this paper, we pro- pose a predictive framework that can estimate online audience demographic attributes based on their browsing histories. Under the proposed framework, first, we retrieve the content of the websites visited by audience, and represent the content as website feature vectors; second, we aggregate the vectors of websites that audience have visited and arrive at feature vectors representing the users; finally, the support vector machine is exploited to predict the audience demographic attributes. The key to achieving good prediction performance is preparing representative features of the audience. Word Embedding, a widely used tech- nique in natural language processing tasks, together with term frequency-inverse document frequency weighting scheme is used in the proposed method. This new representation ap- proach is unsupervised and very easy to implement. The experimental results demonstrate that the new audience feature representation method is more powerful than existing baseline methods, leading to a great improvement in prediction accuracy.
Revenue-based Attribution Modeling for Online Advertising
Oct 18, 2017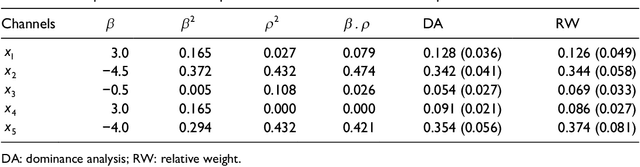
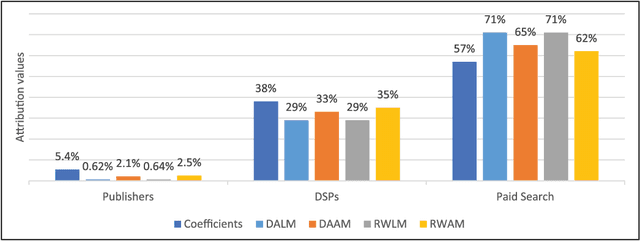


This paper examines and proposes several attribution modeling methods that quantify how revenue should be attributed to online advertising inputs. We adopt and further develop relative importance method, which is based on regression models that have been extensively studied and utilized to investigate the relationship between advertising efforts and market reaction (revenue). Relative importance method aims at decomposing and allocating marginal contributions to the coefficient of determination (R^2) of regression models as attribution values. In particular, we adopt two alternative submethods to perform this decomposition: dominance analysis and relative weight analysis. Moreover, we demonstrate an extension of the decomposition methods from standard linear model to additive model. We claim that our new approaches are more flexible and accurate in modeling the underlying relationship and calculating the attribution values. We use simulation examples to demonstrate the superior performance of our new approaches over traditional methods. We further illustrate the value of our proposed approaches using a real advertising campaign dataset.