 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOTS3D: Hyper-Spherical Optimal Transport for Semantic Alignment of Text-to-3D Generation
Jul 19, 2024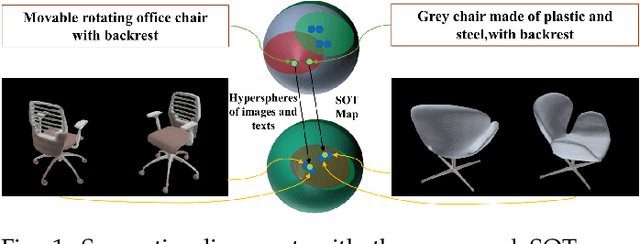
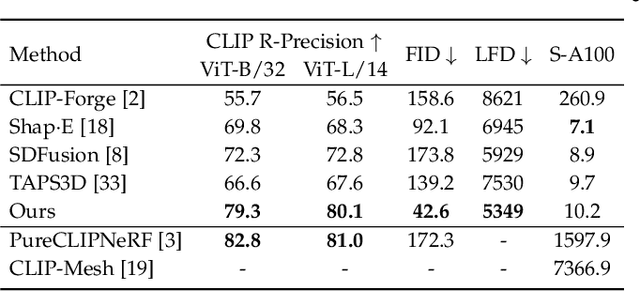
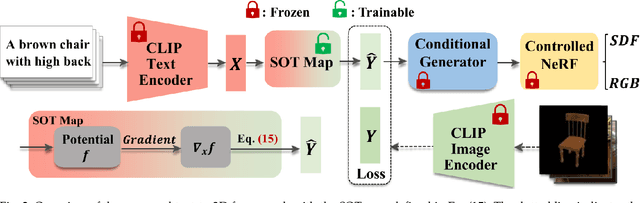
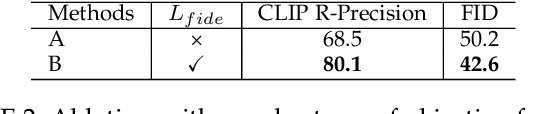
Recent CLIP-guided 3D generation methods have achieved promising results but struggle with generating faithful 3D shapes that conform with input text due to the gap between text and image embeddings. To this end, this paper proposes HOTS3D which makes the first attempt to effectively bridge this gap by aligning text features to the image features with spherical optimal transport (SOT). However, in high-dimensional situations, solving the SOT remains a challenge. To obtain the SOT map for high-dimensional features obtained from CLIP encoding of two modalities, we mathematically formulate and derive the solution based on Villani's theorem, which can directly align two hyper-sphere distributions without manifold exponential maps. Furthermore, we implement it by leveraging input convex neural networks (ICNNs) for the optimal Kantorovich potential. With the optimally mapped features, a diffusion-based generator and a Nerf-based decoder are subsequently utilized to transform them into 3D shapes. Extensive qualitative and qualitative comparisons with state-of-the-arts demonstrate the superiority of the proposed HOTS3D for 3D shape generation, especially on the consistency with text semantics.