 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios
Feb 26, 2026Route-planning agents powered by large language models (LLMs) have emerged as a promising paradigm for supporting everyday human mobility through natural language interaction and tool-mediated decision making. However, systematic evaluation in real-world mobility settings is hindered by diverse routing demands, non-deterministic mapping services, and limited reproducibility. In this study, we introduce MobilityBench, a scalable benchmark for evaluating LLM-based route-planning agents in real-world mobility scenarios. MobilityBench is constructed from large-scale, anonymized real user queries collected from Amap and covers a broad spectrum of route-planning intents across multiple cities worldwide. To enable reproducible, end-to-end evaluation, we design a deterministic API-replay sandbox that eliminates environmental variance from live services. We further propose a multi-dimensional evaluation protocol centered on outcome validity, complemented by assessments of instruction understanding, planning, tool use, and efficiency. Using MobilityBench, we evaluate multiple LLM-based route-planning agents across diverse real-world mobility scenarios and provide an in-depth analysis of their behaviors and performance. Our findings reveal that current models perform competently on Basic information retrieval and Route Planning tasks, yet struggle considerably with Preference-Constrained Route Planning, underscoring significant room for improvement in personalized mobility applications. We publicly release the benchmark data, evaluation toolkit, and documentation at https://github.com/AMAP-ML/MobilityBench .
Generative Organizational Behavior Simulation using Large Language Model based Autonomous Agents: A Holacracy Perspective
Aug 05, 2024

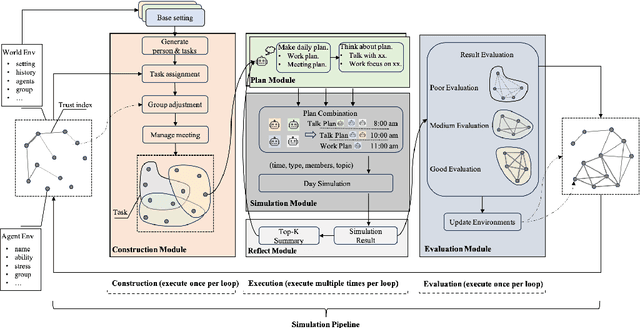

In this paper, we present the technical details and periodic findings of our project, CareerAgent, which aims to build a generative simulation framework for a Holacracy organization using Large Language Model-based Autonomous Agents. Specifically, the simulation framework includes three phases: construction, execution, and evaluation, and it incorporates basic characteristics of individuals, organizations, tasks, and meetings. Through our simulation, we obtained several interesting findings. At the organizational level, an increase in the average values of management competence and functional competence can reduce overall members' stress levels, but it negatively impacts deeper organizational performance measures such as average task completion. At the individual level, both competences can improve members' work performance. From the analysis of social networks, we found that highly competent members selectively participate in certain tasks and take on more responsibilities. Over time, small sub-communities form around these highly competent members within the holacracy. These findings contribute theoretically to the study of organizational science and provide practical insights for managers to understand the organization dynamics.
Towards Efficient Resume Understanding: A Multi-Granularity Multi-Modal Pre-Training Approach
Apr 13, 2024
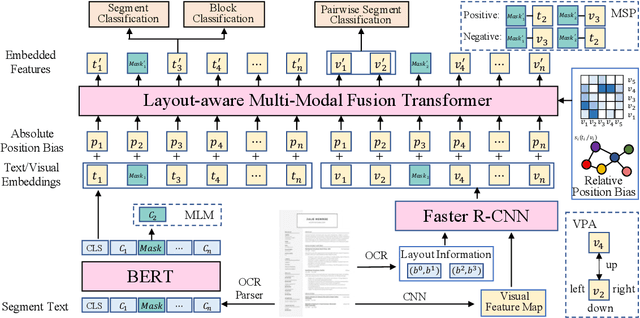


In the contemporary era of widespread online recruitment, resume understanding has been widely acknowledged as a fundamental and crucial task, which aims to extract structured information from resume documents automatically. Compared to the traditional rule-based approaches, the utilization of recently proposed pre-trained document understanding models can greatly enhance the effectiveness of resume understanding. The present approaches have, however, disregarded the hierarchical relations within the structured information presented in resumes, and have difficulty parsing resumes in an efficient manner. To this end, in this paper, we propose a novel model, namely ERU, to achieve efficient resume understanding. Specifically, we first introduce a layout-aware multi-modal fusion transformer for encoding the segments in the resume with integrated textual, visual, and layout information. Then, we design three self-supervised tasks to pre-train this module via a large number of unlabeled resumes. Next, we fine-tune the model with a multi-granularity sequence labeling task to extract structured information from resumes. Finally, extensive experiments on a real-world dataset clearly demonstrate the effectiveness of ERU.