 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Resume Understanding: A Multi-Granularity Multi-Modal Pre-Training Approach
Apr 13, 2024
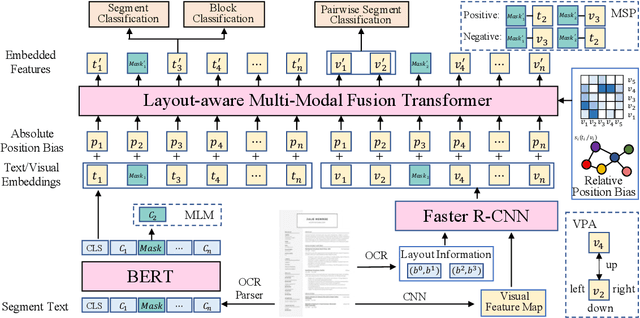


In the contemporary era of widespread online recruitment, resume understanding has been widely acknowledged as a fundamental and crucial task, which aims to extract structured information from resume documents automatically. Compared to the traditional rule-based approaches, the utilization of recently proposed pre-trained document understanding models can greatly enhance the effectiveness of resume understanding. The present approaches have, however, disregarded the hierarchical relations within the structured information presented in resumes, and have difficulty parsing resumes in an efficient manner. To this end, in this paper, we propose a novel model, namely ERU, to achieve efficient resume understanding. Specifically, we first introduce a layout-aware multi-modal fusion transformer for encoding the segments in the resume with integrated textual, visual, and layout information. Then, we design three self-supervised tasks to pre-train this module via a large number of unlabeled resumes. Next, we fine-tune the model with a multi-granularity sequence labeling task to extract structured information from resumes. Finally, extensive experiments on a real-world dataset clearly demonstrate the effectiveness of ERU.
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Apr 10, 2024



Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.