 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDi: Co-evolving Contrastive Diffusion Models for Mixed-type Tabular Synthesis
Paper and Code
Apr 25, 2023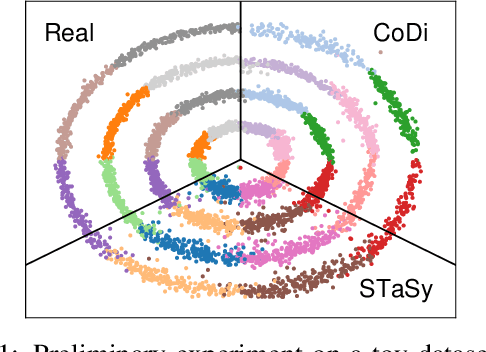
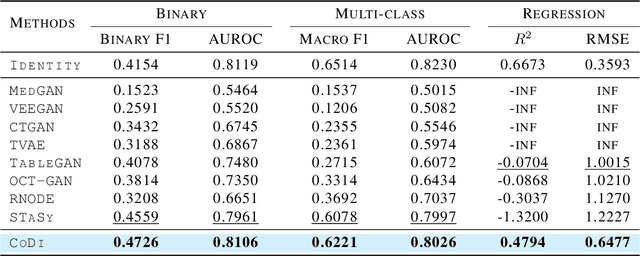
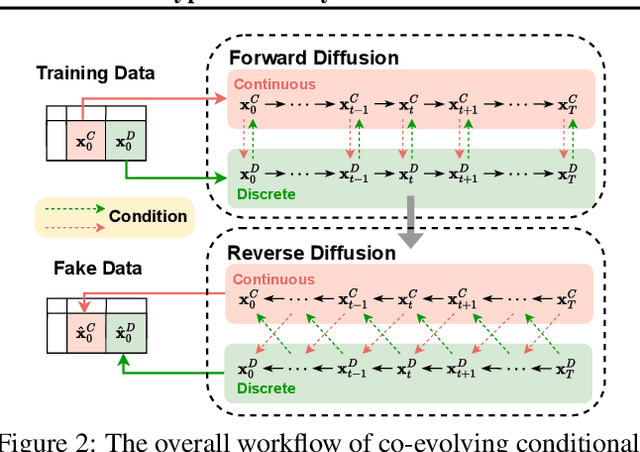
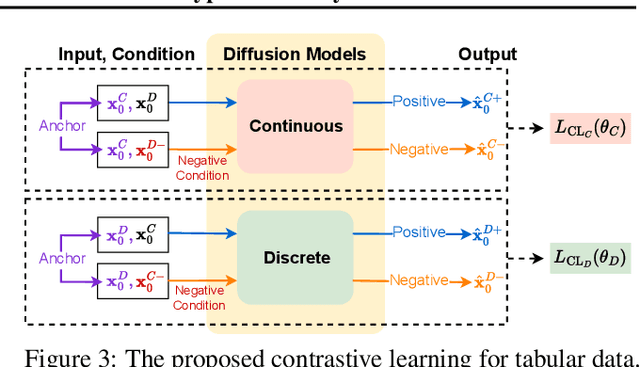
With growing attention to tabular data these days, the attempt to apply a synthetic table to various tasks has been expanded toward various scenarios. Owing to the recent advances in generative modeling, fake data generated by tabular data synthesis models become sophisticated and realistic. However, there still exists a difficulty in modeling discrete variables (columns) of tabular data. In this work, we propose to process continuous and discrete variables separately (but being conditioned on each other) by two diffusion models. The two diffusion models are co-evolved during training by reading conditions from each other. In order to further bind the diffusion models, moreover, we introduce a contrastive learning method with a negative sampling method. In our experiments with 11 real-world tabular datasets and 8 baseline methods, we prove the efficacy of the proposed method, called CoDi.