 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelog Patterns Analyzation using Graph Embedding based on Deep Neural Network
Sep 10, 2019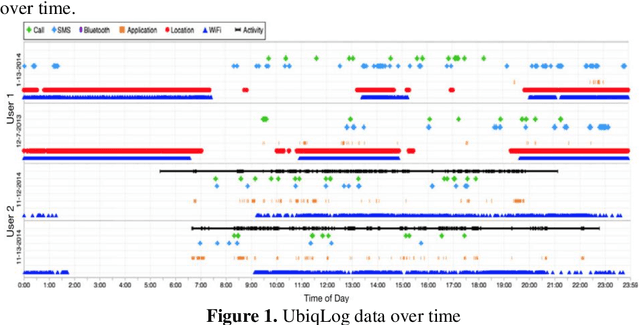
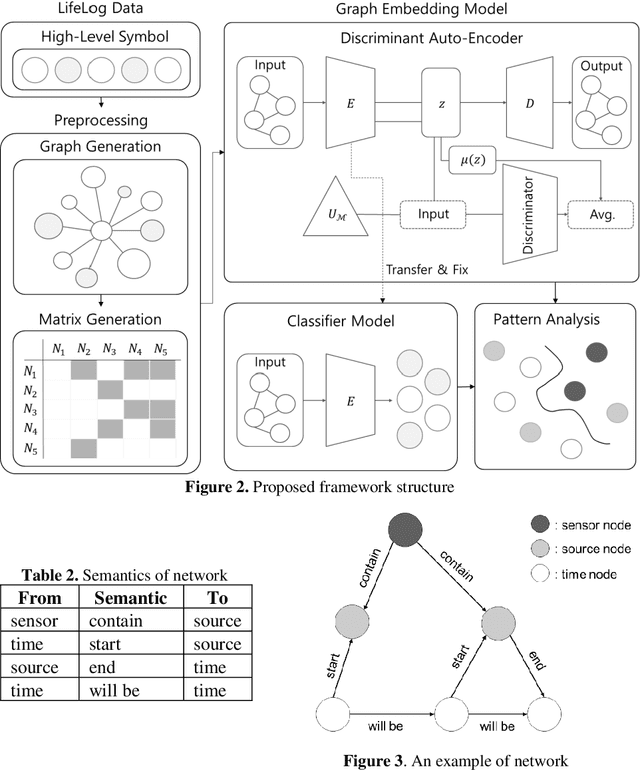
Recently, as the spread of smart devices increases, the amount of data collected through sensors is increasing. A lifelog is a kind of big data to analyze behavior patterns in the daily life of individuals collected from various smart de-vices. However, sensor data is a low-level signal that makes it difficult for hu-mans to recognize the situation directly and cannot express relations clearly. It is also difficult to identify the daily behavior pattern because it records heterogene-ous data by various sensors. In this paper, we propose a method to define a graph structure with node and edge and to extract the daily behavior pattern from the generated lifelog graph. We use the graph convolution method to embeds the lifelog graph and maps it to low dimension. The graph convolution layer im-proves the expressive power of the daily behavior pattern by implanting the life-log graph in the non-Euclidean space and learns the patterns of graphs. Experi-mental results show that the proposed method automatically extracts meaningful user patterns from UbiqLog dataset. In addition, we confirm the usefulness by comparing our method with existing methods to evaluate performance.
Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning
Sep 07, 2019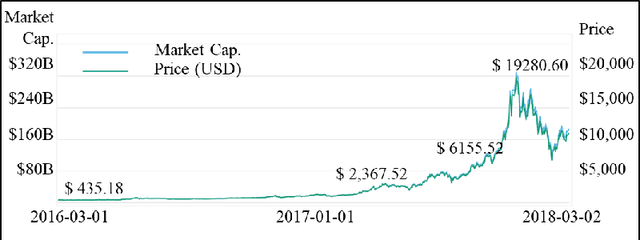


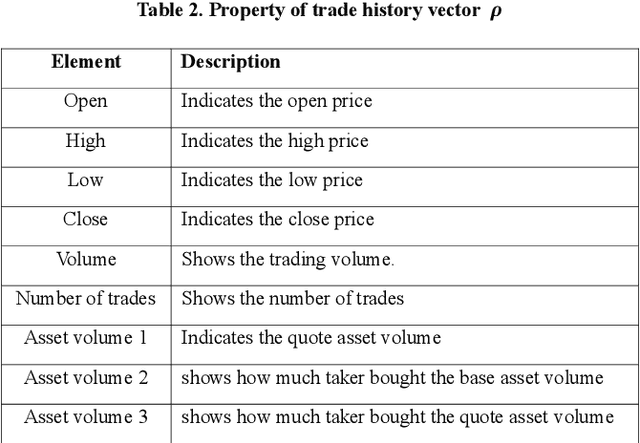
The autonomous trading agent is one of the most actively studied areas of artificial intelligence to solve the capital market portfolio management problem. The two primary goals of the portfolio management problem are maximizing profit and restrainting risk. However, most approaches to this problem solely take account of maximizing returns. Therefore, this paper proposes a deep reinforcement learning based trading agent that can manage the portfolio considering not only profit maximization but also risk restraint. We also propose a new target policy to allow the trading agent to learn to prefer low-risk actions. The new target policy can be reflected in the update by adjusting the greediness for the optimal action through the hyper parameter. The proposed trading agent verifies the performance through the data of the cryptocurrency market. The Cryptocurrency market is the best test-ground for testing our trading agents because of the huge amount of data accumulated every minute and the market volatility is extremely large. As a experimental result, during the test period, our agents achieved a return of 1800% and provided the least risky investment strategy among the existing methods. And, another experiment shows that the agent can maintain robust generalized performance even if market volatility is large or training period is short.
Mature GAIL: Imitation Learning for Low-level and High-dimensional Input using Global Encoder and Cost Transformation
Sep 07, 2019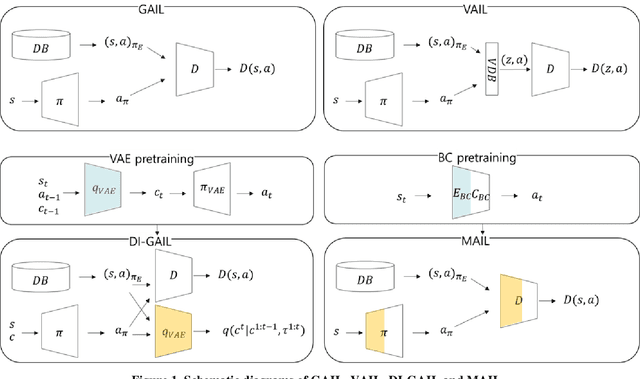
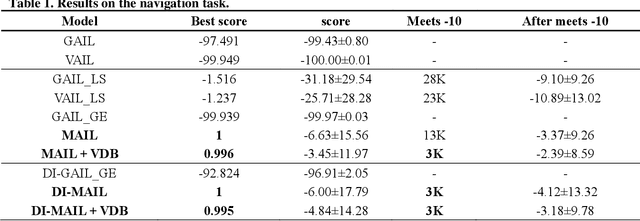
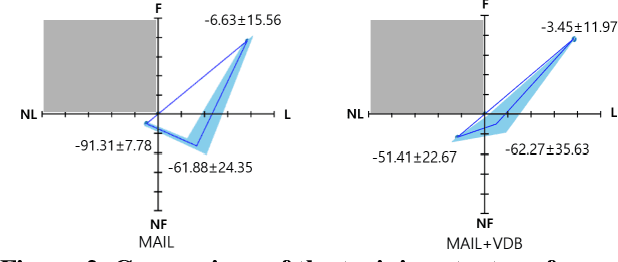
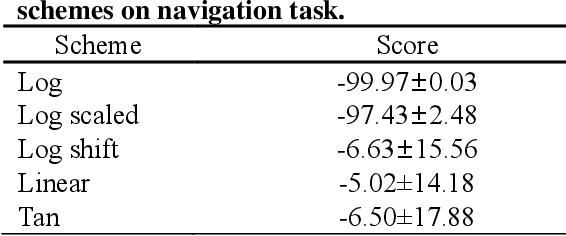
Recently, GAIL framework and various variants have shown remarkable possibilities for solving practical MDP problems. However, detailed researches of low-level, and high-dimensional state input in this framework, such as image sequences, has not been conducted. Furthermore, the cost function learned in the traditional GAIL frame-work only lies on a negative range, acting as a non-penalized reward and making the agent difficult to learn the optimal policy. In this paper, we propose a new algorithm based on the GAIL framework that includes a global encoder and the reward penalization mechanism. The global encoder solves two issues that arise when applying GAIL framework to high-dimensional image state. Also, it is shown that the penalization mechanism provides more adequate reward to the agent, resulting in stable performance improvement. Our approach's potential can be backed up by the fact that it is generally applicable to variants of GAIL framework. We conducted in-depth experiments by applying our methods to various variants of the GAIL framework. And, the results proved that our method significantly improves the performances when it comes to low-level and high-dimensional tasks.