 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMature GAIL: Imitation Learning for Low-level and High-dimensional Input using Global Encoder and Cost Transformation
Sep 07, 2019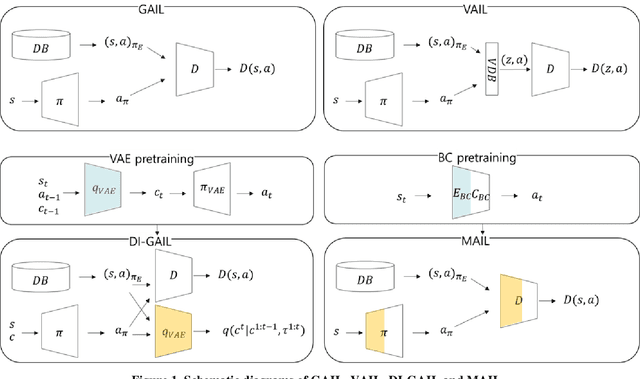
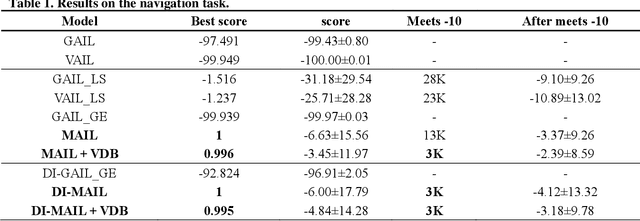
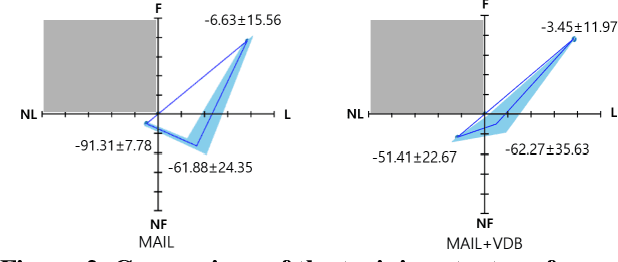
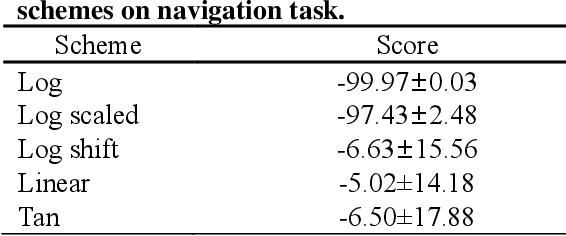
Recently, GAIL framework and various variants have shown remarkable possibilities for solving practical MDP problems. However, detailed researches of low-level, and high-dimensional state input in this framework, such as image sequences, has not been conducted. Furthermore, the cost function learned in the traditional GAIL frame-work only lies on a negative range, acting as a non-penalized reward and making the agent difficult to learn the optimal policy. In this paper, we propose a new algorithm based on the GAIL framework that includes a global encoder and the reward penalization mechanism. The global encoder solves two issues that arise when applying GAIL framework to high-dimensional image state. Also, it is shown that the penalization mechanism provides more adequate reward to the agent, resulting in stable performance improvement. Our approach's potential can be backed up by the fact that it is generally applicable to variants of GAIL framework. We conducted in-depth experiments by applying our methods to various variants of the GAIL framework. And, the results proved that our method significantly improves the performances when it comes to low-level and high-dimensional tasks.