 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Consistent Long-Term Memory for 3D Single Object Tracking
Apr 15, 20263D Single Object Tracking (3D-SOT) aims to localize a target object across a sequence of LiDAR point clouds, given its 3D bounding box in the first frame. Recent methods have adopted a memory-based approach to utilize previously observed features of the target object, but remain limited to only a few recent frames. This work reveals that their temporal capacity is fundamentally constrained to short-term context due to severe temporal feature inconsistency and excessive memory overhead. To this end, we propose a robust long-term 3D-SOT framework, ChronoTrack, which preserves the temporal feature consistency while efficiently aggregating the diverse target features via long-term memory. Based on a compact set of learnable memory tokens, ChronoTrack leverages long-term information through two complementary objectives: a temporal consistency loss and a memory cycle consistency loss. The former enforces feature alignment across frames, alleviating temporal drift and improving the reliability of proposed long-term memory. In parallel, the latter encourages each token to encode diverse and discriminative target representations observed throughout the sequence via memory-point-memory cyclic walks. As a result, ChronoTrack achieves new state-of-the-art performance on multiple 3D-SOT benchmarks, demonstrating its effectiveness in long-term target modeling with compact memory while running at real-time speed of 42 FPS on a single RTX 4090 GPU. The code is available at https://github.com/ujaejoon/ChronoTrack
Auxiliary Descriptive Knowledge for Few-Shot Adaptation of Vision-Language Model
Dec 19, 2025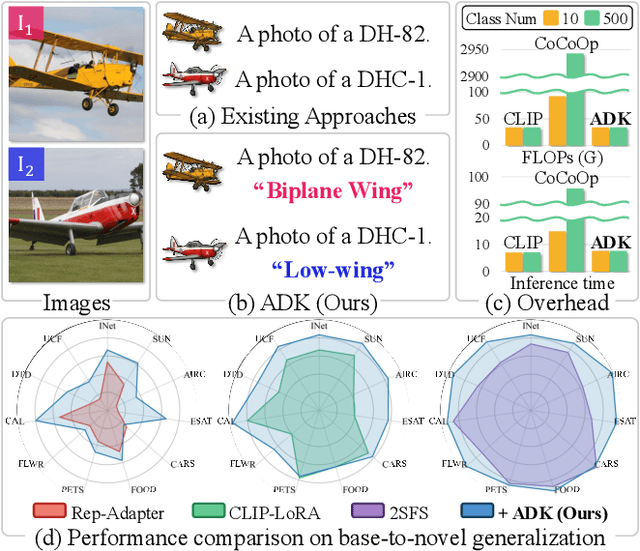
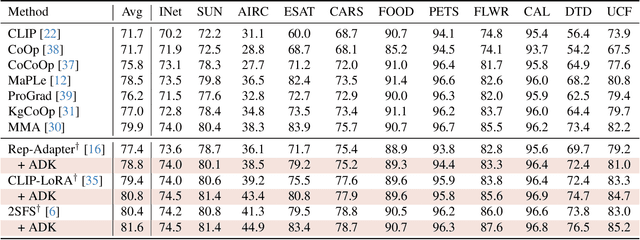
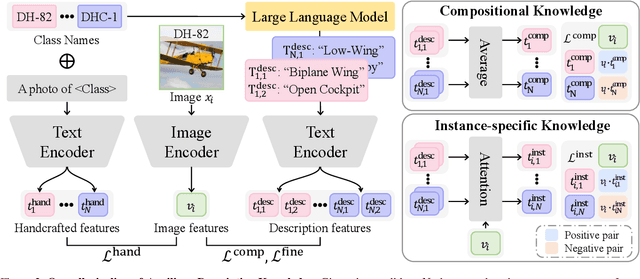
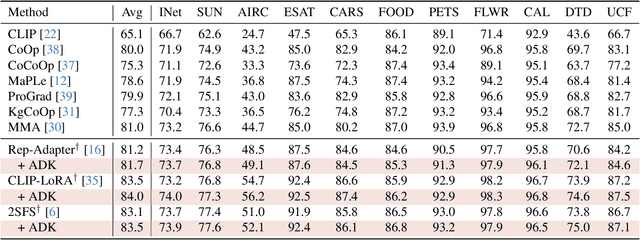
Despite the impressive zero-shot capabilities of Vision-Language Models (VLMs), they often struggle in downstream tasks with distribution shifts from the pre-training data. Few-Shot Adaptation (FSA-VLM) has emerged as a key solution, typically using Parameter-Efficient Fine-Tuning (PEFT) to adapt models with minimal data. However, these PEFT methods are constrained by their reliance on fixed, handcrafted prompts, which are often insufficient to understand the semantics of classes. While some studies have proposed leveraging image-induced prompts to provide additional clues for classification, they introduce prohibitive computational overhead at inference. Therefore, we introduce Auxiliary Descriptive Knowledge (ADK), a novel framework that efficiently enriches text representations without compromising efficiency. ADK first leverages a Large Language Model to generate a rich set of descriptive prompts for each class offline. These pre-computed features are then deployed in two ways: (1) as Compositional Knowledge, an averaged representation that provides rich semantics, especially beneficial when class names are ambiguous or unfamiliar to the VLM; and (2) as Instance-Specific Knowledge, where a lightweight, non-parametric attention mechanism dynamically selects the most relevant descriptions for a given image. This approach provides two additional types of knowledge alongside the handcrafted prompt, thereby facilitating category distinction across various domains. Also, ADK acts as a parameter-free, plug-and-play component that enhances existing PEFT methods. Extensive experiments demonstrate that ADK consistently boosts the performance of multiple PEFT baselines, setting a new state-of-the-art across various scenarios.
White Aggregation and Restoration for Few-shot 3D Point Cloud Semantic Segmentation
Sep 17, 2025Few-Shot 3D Point Cloud Segmentation (FS-PCS) aims to predict per-point labels for an unlabeled point cloud, given only a few labeled examples. To extract discriminative representations from the limited support set, existing methods have constructed prototypes using conventional algorithms such as farthest point sampling. However, we point out that its initial randomness significantly affects FS-PCS performance and that the prototype generation process remains underexplored despite its prevalence. This motivates us to investigate an advanced prototype generation method based on attention mechanism. Despite its potential, we found that vanilla module suffers from the distributional gap between learnable prototypical tokens and support features. To overcome this, we propose White Aggregation and Restoration Module (WARM), which resolves the misalignment by sandwiching cross-attention between whitening and coloring transformations. Specifically, whitening aligns the support features to prototypical tokens before attention process, and subsequently coloring restores the original distribution to the attended tokens. This simple yet effective design enables robust attention, thereby generating representative prototypes by capturing the semantic relationships among support features. Our method achieves state-of-the-art performance with a significant margin on multiple FS-PCS benchmarks, demonstrating its effectiveness through extensive experiments.
Temporal Alignment-Free Video Matching for Few-shot Action Recognition
Apr 08, 2025



Few-Shot Action Recognition (FSAR) aims to train a model with only a few labeled video instances. A key challenge in FSAR is handling divergent narrative trajectories for precise video matching. While the frame- and tuple-level alignment approaches have been promising, their methods heavily rely on pre-defined and length-dependent alignment units (e.g., frames or tuples), which limits flexibility for actions of varying lengths and speeds. In this work, we introduce a novel TEmporal Alignment-free Matching (TEAM) approach, which eliminates the need for temporal units in action representation and brute-force alignment during matching. Specifically, TEAM represents each video with a fixed set of pattern tokens that capture globally discriminative clues within the video instance regardless of action length or speed, ensuring its flexibility. Furthermore, TEAM is inherently efficient, using token-wise comparisons to measure similarity between videos, unlike existing methods that rely on pairwise comparisons for temporal alignment. Additionally, we propose an adaptation process that identifies and removes common information across classes, establishing clear boundaries even between novel categories. Extensive experiments demonstrate the effectiveness of TEAM. Codes are available at github.com/leesb7426/TEAM.
Foreground-Covering Prototype Generation and Matching for SAM-Aided Few-Shot Segmentation
Jan 01, 2025


We propose Foreground-Covering Prototype Generation and Matching to resolve Few-Shot Segmentation (FSS), which aims to segment target regions in unlabeled query images based on labeled support images. Unlike previous research, which typically estimates target regions in the query using support prototypes and query pixels, we utilize the relationship between support and query prototypes. To achieve this, we utilize two complementary features: SAM Image Encoder features for pixel aggregation and ResNet features for class consistency. Specifically, we construct support and query prototypes with SAM features and distinguish query prototypes of target regions based on ResNet features. For the query prototype construction, we begin by roughly guiding foreground regions within SAM features using the conventional pseudo-mask, then employ iterative cross-attention to aggregate foreground features into learnable tokens. Here, we discover that the cross-attention weights can effectively alternate the conventional pseudo-mask. Therefore, we use the attention-based pseudo-mask to guide ResNet features to focus on the foreground, then infuse the guided ResNet feature into the learnable tokens to generate class-consistent query prototypes. The generation of the support prototype is conducted symmetrically to that of the query one, with the pseudo-mask replaced by the ground-truth mask. Finally, we compare these query prototypes with support ones to generate prompts, which subsequently produce object masks through the SAM Mask Decoder. Our state-of-the-art performances on various datasets validate the effectiveness of the proposed method for FSS. Our official code is available at https://github.com/SuhoPark0706/FCP
Progressive Proxy Anchor Propagation for Unsupervised Semantic Segmentation
Jul 17, 2024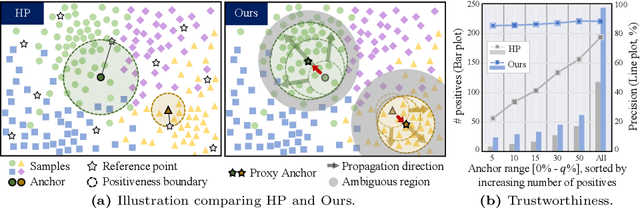
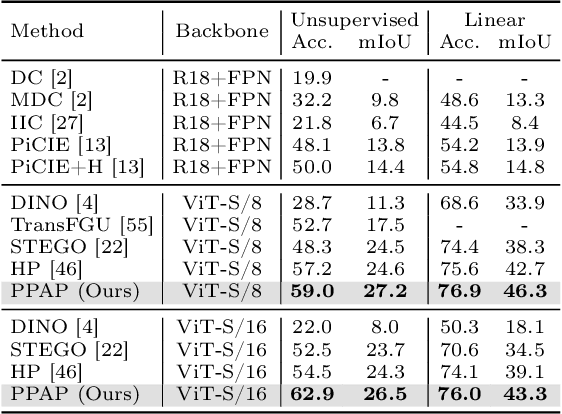
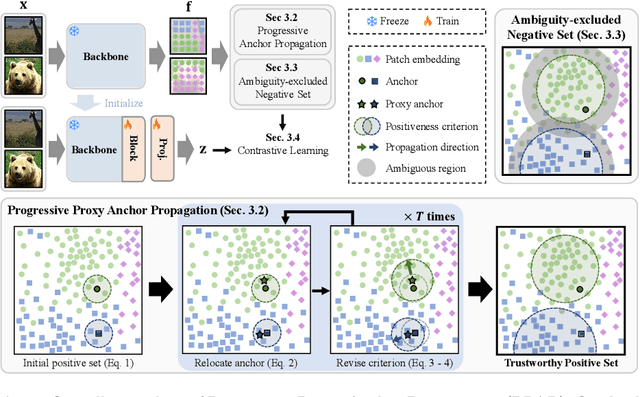
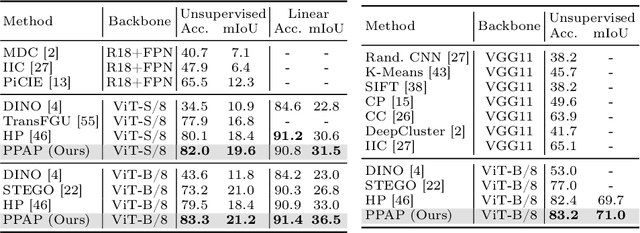
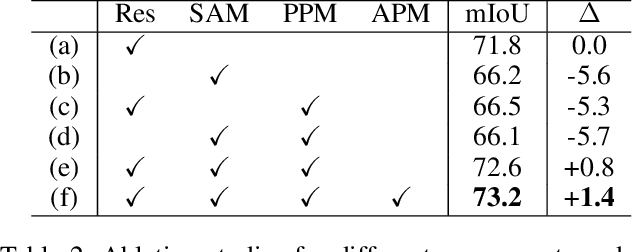
The labor-intensive labeling for semantic segmentation has spurred the emergence of Unsupervised Semantic Segmentation. Recent studies utilize patch-wise contrastive learning based on features from image-level self-supervised pretrained models. However, relying solely on similarity-based supervision from image-level pretrained models often leads to unreliable guidance due to insufficient patch-level semantic representations. To address this, we propose a Progressive Proxy Anchor Propagation (PPAP) strategy. This method gradually identifies more trustworthy positives for each anchor by relocating its proxy to regions densely populated with semantically similar samples. Specifically, we initially establish a tight boundary to gather a few reliable positive samples around each anchor. Then, considering the distribution of positive samples, we relocate the proxy anchor towards areas with a higher concentration of positives and adjust the positiveness boundary based on the propagation degree of the proxy anchor. Moreover, to account for ambiguous regions where positive and negative samples may coexist near the positiveness boundary, we introduce an instance-wise ambiguous zone. Samples within these zones are excluded from the negative set, further enhancing the reliability of the negative set. Our state-of-the-art performances on various datasets validate the effectiveness of the proposed method for Unsupervised Semantic Segmentation.
Mitigating Background Shift in Class-Incremental Semantic Segmentation
Jul 16, 2024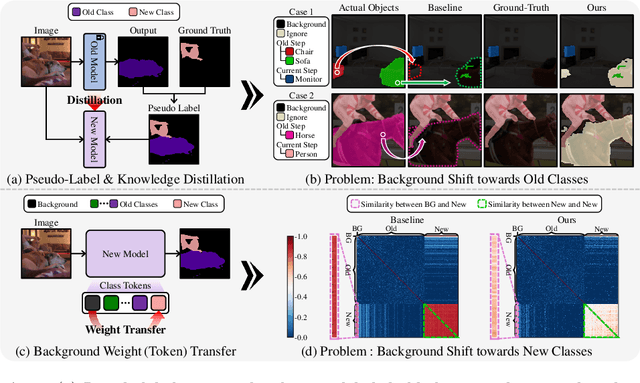
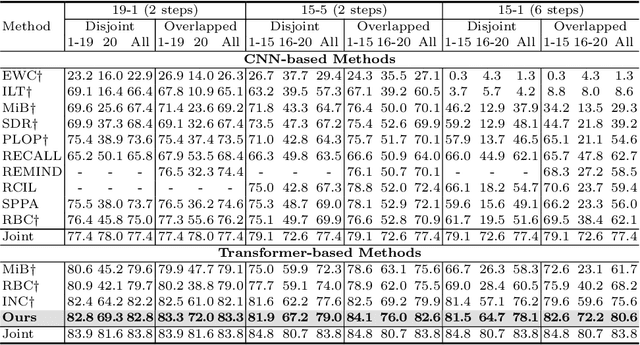
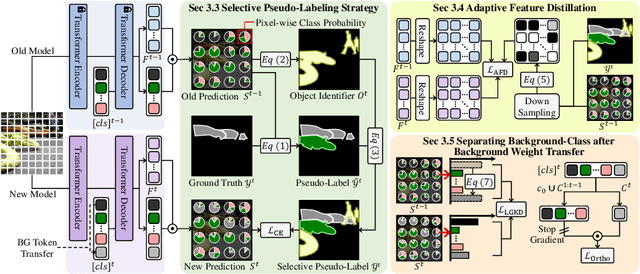
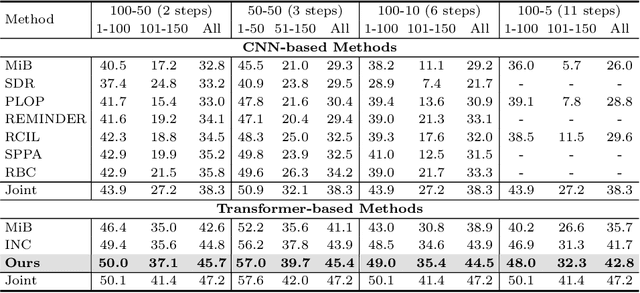
Class-Incremental Semantic Segmentation(CISS) aims to learn new classes without forgetting the old ones, using only the labels of the new classes. To achieve this, two popular strategies are employed: 1) pseudo-labeling and knowledge distillation to preserve prior knowledge; and 2) background weight transfer, which leverages the broad coverage of background in learning new classes by transferring background weight to the new class classifier. However, the first strategy heavily relies on the old model in detecting old classes while undetected pixels are regarded as the background, thereby leading to the background shift towards the old classes(i.e., misclassification of old class as background). Additionally, in the case of the second approach, initializing the new class classifier with background knowledge triggers a similar background shift issue, but towards the new classes. To address these issues, we propose a background-class separation framework for CISS. To begin with, selective pseudo-labeling and adaptive feature distillation are to distill only trustworthy past knowledge. On the other hand, we encourage the separation between the background and new classes with a novel orthogonal objective along with label-guided output distillation. Our state-of-the-art results validate the effectiveness of these proposed methods.
Task-Disruptive Background Suppression for Few-Shot Segmentation
Dec 26, 2023Few-shot segmentation aims to accurately segment novel target objects within query images using only a limited number of annotated support images. The recent works exploit support background as well as its foreground to precisely compute the dense correlations between query and support. However, they overlook the characteristics of the background that generally contains various types of objects. In this paper, we highlight this characteristic of background which can bring problematic cases as follows: (1) when the query and support backgrounds are dissimilar and (2) when objects in the support background are similar to the target object in the query. Without any consideration of the above cases, adopting the entire support background leads to a misprediction of the query foreground as background. To address this issue, we propose Task-disruptive Background Suppression (TBS), a module to suppress those disruptive support background features based on two spatial-wise scores: query-relevant and target-relevant scores. The former aims to mitigate the impact of unshared features solely existing in the support background, while the latter aims to reduce the influence of target-similar support background features. Based on these two scores, we define a query background relevant score that captures the similarity between the backgrounds of the query and the support, and utilize it to scale support background features to adaptively restrict the impact of disruptive support backgrounds. Our proposed method achieves state-of-the-art performance on PASCAL-5 and COCO-20 datasets on 1-shot segmentation. Our official code is available at github.com/SuhoPark0706/TBSNet.
Correlation-guided Query-Dependency Calibration in Video Representation Learning for Temporal Grounding
Nov 18, 2023



Recent endeavors in video temporal grounding enforce strong cross-modal interactions through attention mechanisms to overcome the modality gap between video and text query. However, previous works treat all video clips equally regardless of their semantic relevance with the text query in attention modules. In this paper, our goal is to provide clues for query-associated video clips within the crossmodal encoding process. With our Correlation-Guided Detection Transformer~(CG-DETR), we explore the appropriate clip-wise degree of cross-modal interactions and how to exploit such degrees for prediction. First, we design an adaptive cross-attention layer with dummy tokens. Dummy tokens conditioned by text query take a portion of the attention weights, preventing irrelevant video clips from being represented by the text query. Yet, not all word tokens equally inherit the text query's correlation to video clips. Thus, we further guide the cross-attention map by inferring the fine-grained correlation between video clips and words. We enable this by learning a joint embedding space for high-level concepts, i.e., moment and sentence level, and inferring the clip-word correlation. Lastly, we use a moment-adaptive saliency detector to exploit each video clip's degrees of text engagement. We validate the superiority of CG-DETR with the state-of-the-art results on various benchmarks for both moment retrieval and highlight detection. Codes are available at https://github.com/wjun0830/CGDETR.
Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification
Jul 28, 2023The difficulty of the fine-grained image classification mainly comes from a shared overall appearance across classes. Thus, recognizing discriminative details, such as eyes and beaks for birds, is a key in the task. However, this is particularly challenging when training data is limited. To address this, we propose Task Discrepancy Maximization (TDM), a task-oriented channel attention method tailored for fine-grained few-shot classification with two novel modules Support Attention Module (SAM) and Query Attention Module (QAM). SAM highlights channels encoding class-wise discriminative features, while QAM assigns higher weights to object-relevant channels of the query. Based on these submodules, TDM produces task-adaptive features by focusing on channels encoding class-discriminative details and possessed by the query at the same time, for accurate class-sensitive similarity measure between support and query instances. While TDM influences high-level feature maps by task-adaptive calibration of channel-wise importance, we further introduce Instance Attention Module (IAM) operating in intermediate layers of feature extractors to instance-wisely highlight object-relevant channels, by extending QAM. The merits of TDM and IAM and their complementary benefits are experimentally validated in fine-grained few-shot classification tasks. Moreover, IAM is also shown to be effective in coarse-grained and cross-domain few-shot classifications.