 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy In-Context Learning Transformers are Tabular Data Classifiers
May 22, 2024The recently introduced TabPFN pretrains an In-Context Learning (ICL) transformer on synthetic data to perform tabular data classification. As synthetic data does not share features or labels with real-world data, the underlying mechanism that contributes to the success of this method remains unclear. This study provides an explanation by demonstrating that ICL-transformers acquire the ability to create complex decision boundaries during pretraining. To validate our claim, we develop a novel forest dataset generator which creates datasets that are unrealistic, but have complex decision boundaries. Our experiments confirm the effectiveness of ICL-transformers pretrained on this data. Furthermore, we create TabForestPFN, the ICL-transformer pretrained on both the original TabPFN synthetic dataset generator and our forest dataset generator. By fine-tuning this model, we reach the current state-of-the-art on tabular data classification. Code is available at https://github.com/FelixdenBreejen/TabForestPFN.
Fine-Tuning the Retrieval Mechanism for Tabular Deep Learning
Nov 13, 2023


While interests in tabular deep learning has significantly grown, conventional tree-based models still outperform deep learning methods. To narrow this performance gap, we explore the innovative retrieval mechanism, a methodology that allows neural networks to refer to other data points while making predictions. Our experiments reveal that retrieval-based training, especially when fine-tuning the pretrained TabPFN model, notably surpasses existing methods. Moreover, the extensive pretraining plays a crucial role to enhance the performance of the model. These insights imply that blending the retrieval mechanism with pretraining and transfer learning schemes offers considerable potential for advancing the field of tabular deep learning.
SuperNet in Neural Architecture Search: A Taxonomic Survey
Apr 08, 2022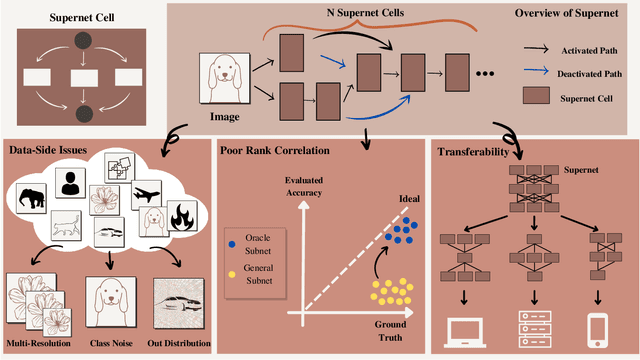
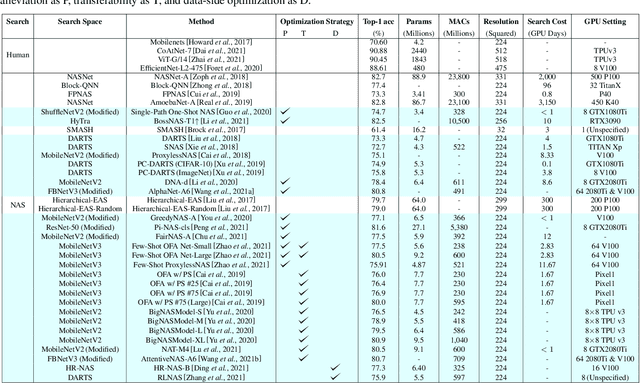
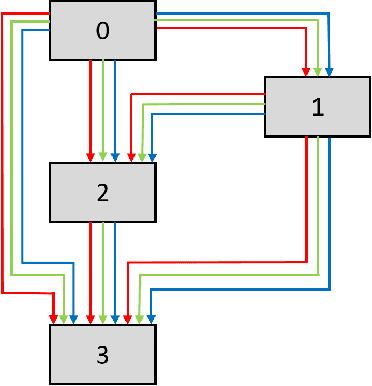
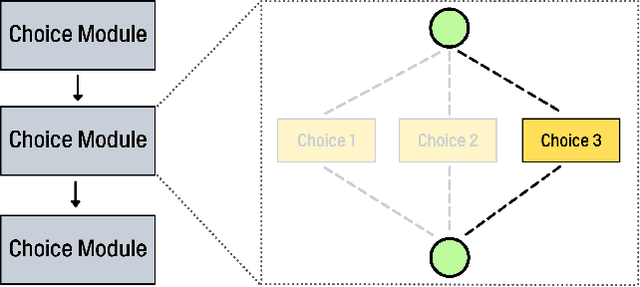
Deep Neural Networks (DNN) have made significant progress in a wide range of visual recognition tasks such as image classification, object detection, and semantic segmentation. The evolution of convolutional architectures has led to better performance by incurring expensive computational costs. In addition, network design has become a difficult task, which is labor-intensive and requires a high level of domain knowledge. To mitigate such issues, there have been studies for a variety of neural architecture search methods that automatically search for optimal architectures, achieving models with impressive performance that outperform human-designed counterparts. This survey aims to provide an overview of existing works in this field of research and specifically focus on the supernet optimization that builds a neural network that assembles all the architectures as its sub models by using weight sharing. We aim to accomplish that by categorizing supernet optimization by proposing them as solutions to the common challenges found in the literature: data-side optimization, poor rank correlation alleviation, and transferable NAS for a number of deployment scenarios.