 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning
Jun 06, 2021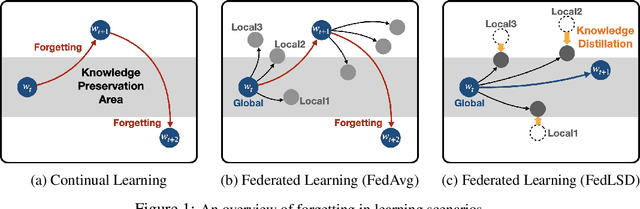


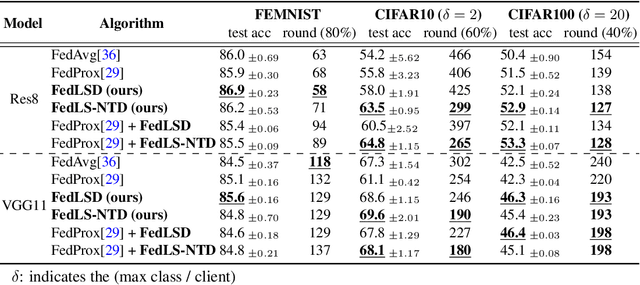
In Federated Learning (FL), a strong global model is collaboratively learned by aggregating the clients' locally trained models. Although this allows no need to access clients' data directly, the global model's convergence often suffers from data heterogeneity. This paper suggests that forgetting could be the bottleneck of global convergence. We observe that fitting on biased local distribution shifts the feature on global distribution and results in forgetting of global knowledge. We consider this phenomenon as an analogy to Continual Learning, which also faces catastrophic forgetting when fitted on the new task distribution. Based on our findings, we hypothesize that tackling down the forgetting in local training relives the data heterogeneity problem. To this end, we propose a simple yet effective framework Federated Local Self-Distillation (FedLSD), which utilizes the global knowledge on locally available data. By following the global perspective on local data, FedLSD encourages the learned features to preserve global knowledge and have consistent views across local models, thus improving convergence without compromising data privacy. Under our framework, we further extend FedLSD to FedLS-NTD, which only considers the not-true class signals to compensate noisy prediction of the global model. We validate that both FedLSD and FedLS-NTD significantly improve the performance in standard FL benchmarks in various setups, especially in the extreme data heterogeneity cases.
Sequential Likelihood-Free Inference with Implicit Surrogate Proposal
Oct 15, 2020



Bayesian inference without the access of likelihood, called likelihood-free inference, is highlighted in simulation to yield a more realistic simulation result. Recent research updates an approximate posterior sequentially with the cumulative simulation input-output pairs over inference rounds. This paper observes that previous algorithms with Monte-Carlo Markov Chain present low accuracy for inference on a simulation with a multi-modal posterior due to the mode collapse of MCMC. From the observation, we propose an implicit sampling method, Implicit Surrogate Proposal (ISP), to draw balanced simulation inputs at each round. The resolution of mode collapse comes from two mechanisms: 1) a flexible surrogate proposal density estimator and 2) a parallel explored samples to train the surrogate density model. We demonstrate that ISP outperforms the baseline algorithms in multi-modal simulations.