 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Holistic and Automated Evaluation Framework for Multi-Level Comprehension of LLMs in Book-Length Contexts
Aug 27, 2025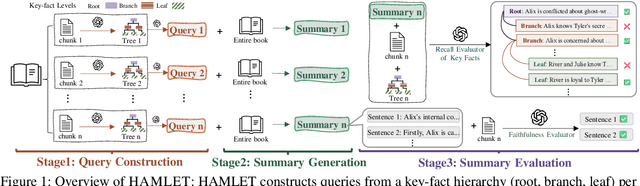


We introduce HAMLET, a holistic and automated framework for evaluating the long-context comprehension of large language models (LLMs). HAMLET structures source texts into a three-level key-fact hierarchy at root-, branch-, and leaf-levels, and employs query-focused summarization to evaluate how well models recall and faithfully represent information at each level. To validate the reliability of our fully automated pipeline, we conduct a systematic human study, showing that our automatic evaluation achieves over 90% agreement with expert human judgments, while reducing the cost by up to 25 times. HAMLET reveals that LLMs struggle with fine-grained comprehension, especially at the leaf level, and are sensitive to positional effects like the lost-in-the-middle. Analytical queries pose greater challenges than narrative ones, and consistent performance gaps emerge between open-source and proprietary models, as well as across model scales. Our code and dataset are publicly available at https://github.com/DISL-Lab/HAMLET.
ReFeed: Multi-dimensional Summarization Refinement with Reflective Reasoning on Feedback
Mar 27, 2025Summarization refinement faces challenges when extending to multi-dimension. In this paper, we introduce ReFeed, a powerful summarization refinement pipeline that enhances multiple dimensions through reflective reasoning on feedback. To achieve this, we release SumFeed-CoT, a large-scale Long-CoT-based dataset optimized for training a lightweight model with reflective reasoning. Our experiments reveal how the number of dimensions, feedback exposure, and reasoning policy influence refinement performance, highlighting reflective reasoning and simultaneously addressing multiple feedback is crucial to mitigate trade-off between dimensions. Furthermore, ReFeed is robust to noisy feedback and feedback order. Lastly, our finding emphasizes that creating data with a proper goal and guideline constitutes a fundamental pillar of effective reasoning. The dataset and model will be released.
Learning to Verify Summary Facts with Fine-Grained LLM Feedback
Dec 14, 2024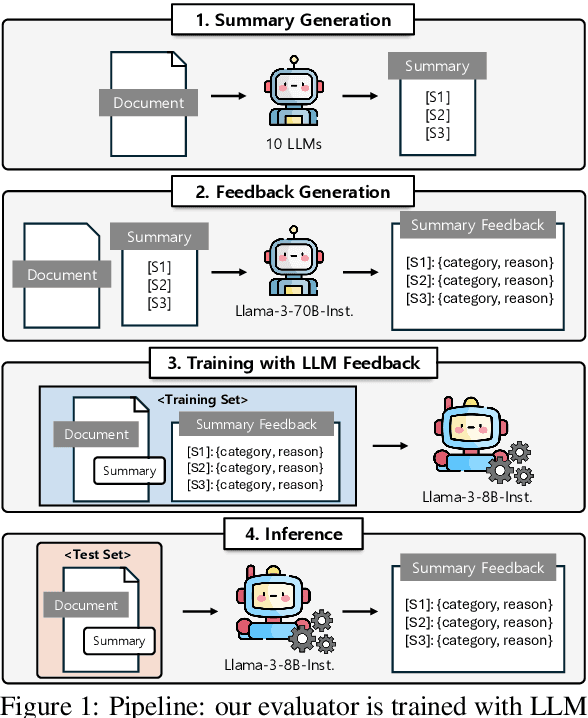
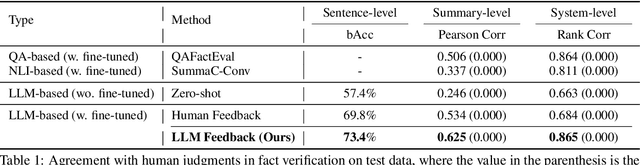


Training automatic summary fact verifiers often faces the challenge of a lack of human-labeled data. In this paper, we explore alternative way of leveraging Large Language Model (LLM) generated feedback to address the inherent limitation of using human-labeled data. We introduce FineSumFact, a large-scale dataset containing fine-grained factual feedback on summaries. We employ 10 distinct LLMs for diverse summary generation and Llama-3-70B-Instruct for feedback. We utilize this dataset to fine-tune the lightweight open-source model Llama-3-8B-Instruct, optimizing resource efficiency while maintaining high performance. Our experimental results reveal that the model trained on extensive LLM-generated datasets surpasses that trained on smaller human-annotated datasets when evaluated using human-generated test sets. Fine-tuning fact verification models with LLM feedback can be more effective and cost-efficient than using human feedback. The dataset is available at https://github.com/DISL-Lab/FineSumFact.
Learning to Summarize from LLM-generated Feedback
Oct 17, 2024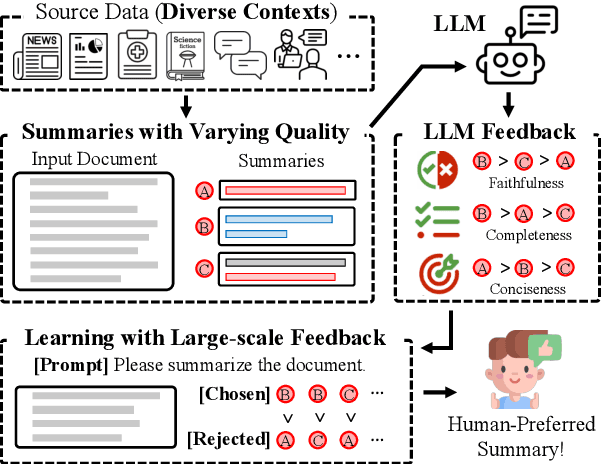


Developing effective text summarizers remains a challenge due to issues like hallucinations, key information omissions, and verbosity in LLM-generated summaries. This work explores using LLM-generated feedback to improve summary quality by aligning the summaries with human preferences for faithfulness, completeness, and conciseness. We introduce FeedSum, a large-scale dataset containing multi-dimensional LLM feedback on summaries of varying quality across diverse domains. Our experiments show how feedback quality, dimensionality, and granularity influence preference learning, revealing that high-quality, multi-dimensional, fine-grained feedback significantly improves summary generation. We also compare two methods for using this feedback: supervised fine-tuning and direct preference optimization. Finally, we introduce SummLlama3-8b, a model that outperforms the nearly 10x larger Llama3-70b-instruct in generating human-preferred summaries, demonstrating that smaller models can achieve superior performance with appropriate training. The full dataset will be released soon. The SummLlama3-8B model is now available at https://huggingface.co/DISLab/SummLlama3-8B.