 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleting Missing Annotation: Multi-Agent Debate for Accurate and Scalable Relevant Assessment for IR Benchmarks
Feb 06, 2026Information retrieval (IR) evaluation remains challenging due to incomplete IR benchmark datasets that contain unlabeled relevant chunks. While LLMs and LLM-human hybrid strategies reduce costly human effort, they remain prone to LLM overconfidence and ineffective AI-to-human escalation. To address this, we propose DREAM, a multi-round debate-based relevance assessment framework with LLM agents, built on opposing initial stances and iterative reciprocal critique. Through our agreement-based debate, it yields more accurate labeling for certain cases and more reliable AI-to-human escalation for uncertain ones, achieving 95.2% labeling accuracy with only 3.5% human involvement. Using DREAM, we build BRIDGE, a refined benchmark that mitigates evaluation bias and enables fairer retriever comparison by uncovering 29,824 missing relevant chunks. We then re-benchmark IR systems and extend evaluation to RAG, showing that unaddressed holes not only distort retriever rankings but also drive retrieval-generation misalignment. The relevance assessment framework is available at https: //github.com/DISL-Lab/DREAM-ICLR-26; and the BRIDGE dataset is available at https://github.com/DISL-Lab/BRIDGE-Benchmark.
Towards a Holistic and Automated Evaluation Framework for Multi-Level Comprehension of LLMs in Book-Length Contexts
Aug 27, 2025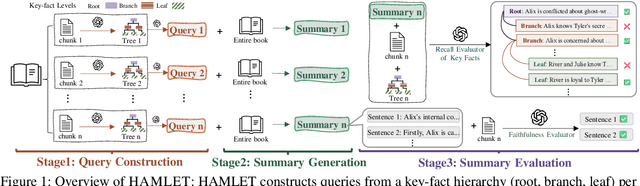
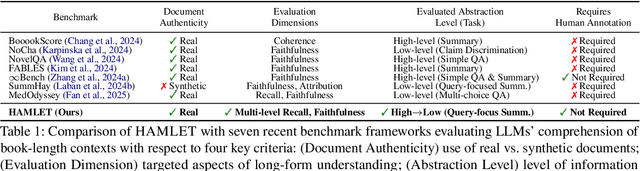


We introduce HAMLET, a holistic and automated framework for evaluating the long-context comprehension of large language models (LLMs). HAMLET structures source texts into a three-level key-fact hierarchy at root-, branch-, and leaf-levels, and employs query-focused summarization to evaluate how well models recall and faithfully represent information at each level. To validate the reliability of our fully automated pipeline, we conduct a systematic human study, showing that our automatic evaluation achieves over 90% agreement with expert human judgments, while reducing the cost by up to 25 times. HAMLET reveals that LLMs struggle with fine-grained comprehension, especially at the leaf level, and are sensitive to positional effects like the lost-in-the-middle. Analytical queries pose greater challenges than narrative ones, and consistent performance gaps emerge between open-source and proprietary models, as well as across model scales. Our code and dataset are publicly available at https://github.com/DISL-Lab/HAMLET.
Learning to Verify Summary Facts with Fine-Grained LLM Feedback
Dec 14, 2024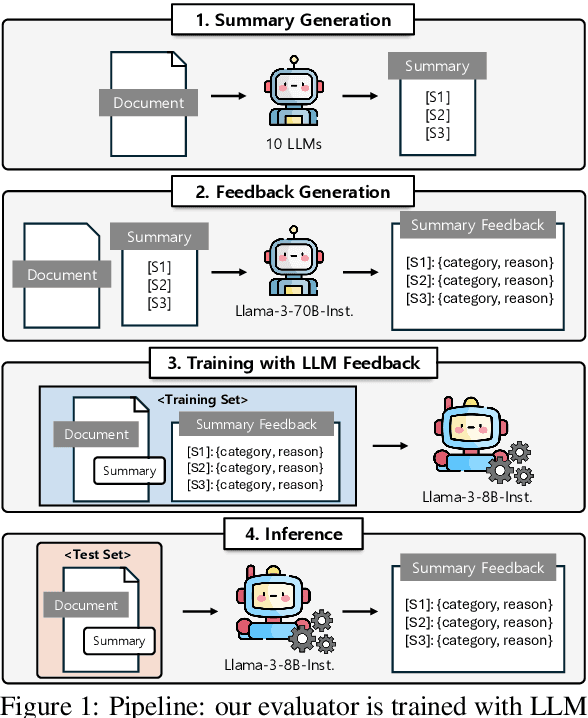
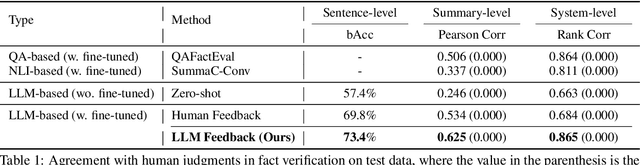


Training automatic summary fact verifiers often faces the challenge of a lack of human-labeled data. In this paper, we explore alternative way of leveraging Large Language Model (LLM) generated feedback to address the inherent limitation of using human-labeled data. We introduce FineSumFact, a large-scale dataset containing fine-grained factual feedback on summaries. We employ 10 distinct LLMs for diverse summary generation and Llama-3-70B-Instruct for feedback. We utilize this dataset to fine-tune the lightweight open-source model Llama-3-8B-Instruct, optimizing resource efficiency while maintaining high performance. Our experimental results reveal that the model trained on extensive LLM-generated datasets surpasses that trained on smaller human-annotated datasets when evaluated using human-generated test sets. Fine-tuning fact verification models with LLM feedback can be more effective and cost-efficient than using human feedback. The dataset is available at https://github.com/DISL-Lab/FineSumFact.