 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixCo: Mix-up Contrastive Learning for Visual Representation
Paper and Code
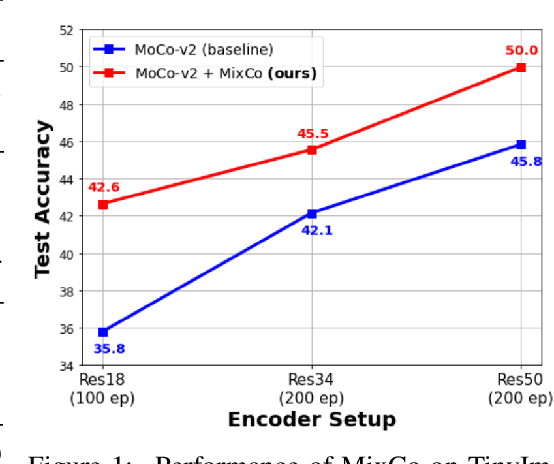
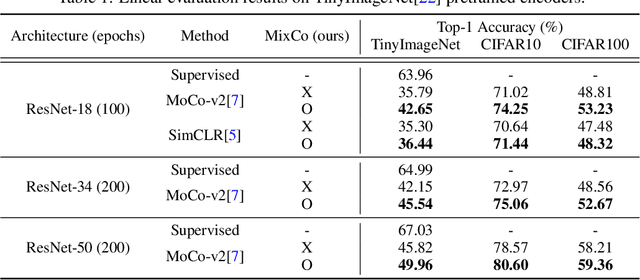


Contrastive learning has shown remarkable results in recent self-supervised approaches for visual representation. By learning to contrast positive pairs' representation from the corresponding negatives pairs, one can train good visual representations without human annotations. This paper proposes Mix-up Contrast (MixCo), which extends the contrastive learning concept to semi-positives encoded from the mix-up of positive and negative images. MixCo aims to learn the relative similarity of representations, reflecting how much the mixed images have the original positives. We validate the efficacy of MixCo when applied to the recent self-supervised learning algorithms under the standard linear evaluation protocol on TinyImageNet, CIFAR10, and CIFAR100. In the experiments, MixCo consistently improves test accuracy. Remarkably, the improvement is more significant when the learning capacity (e.g., model size) is limited, suggesting that MixCo might be more useful in real-world scenarios.