 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Updates of a Pre-trained Model for Few-shot Learning
Paper and Code
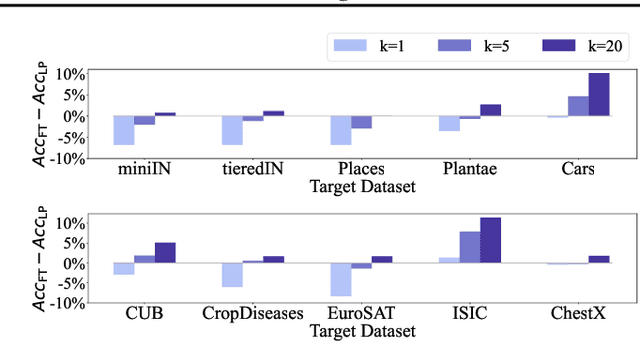
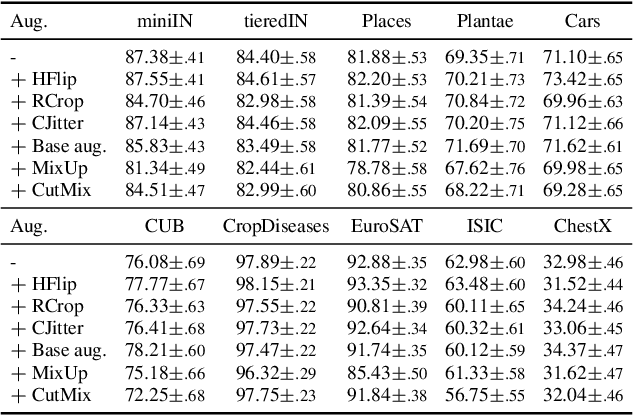
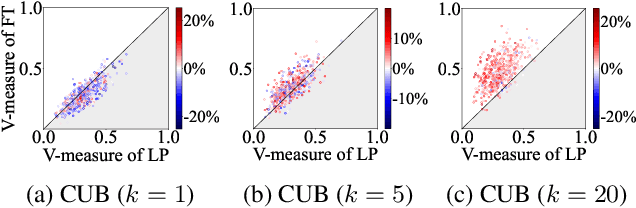
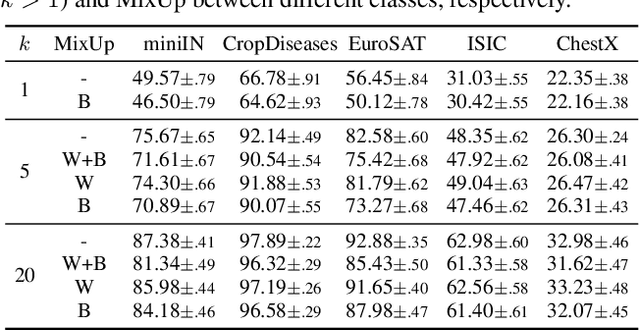
Most of the recent few-shot learning algorithms are based on transfer learning, where a model is pre-trained using a large amount of source data, and the pre-trained model is updated using a small amount of target data afterward. In transfer-based few-shot learning, sophisticated pre-training methods have been widely studied for universal and improved representation. However, there is little study on updating pre-trained models for few-shot learning. In this paper, we compare the two popular updating methods, fine-tuning (i.e., updating the entire network) and linear probing (i.e., updating only the linear classifier), considering the distribution shift between the source and target data. We find that fine-tuning is better than linear probing as the number of samples increases, regardless of distribution shift. Next, we investigate the effectiveness and ineffectiveness of data augmentation when pre-trained models are fine-tuned. Our fundamental analyses demonstrate that careful considerations of the details about updating pre-trained models are required for better few-shot performance.