 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
VarDrop: Enhancing Training Efficiency by Reducing Variate Redundancy in Periodic Time Series Forecasting
Jan 24, 2025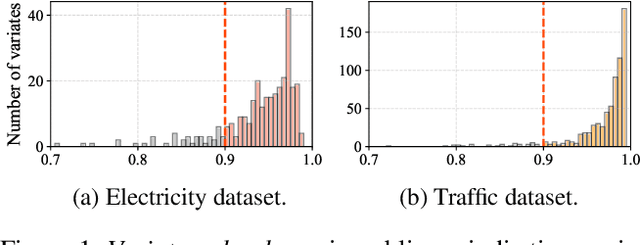
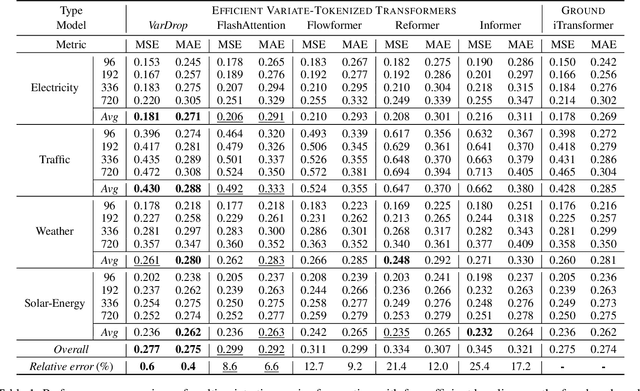
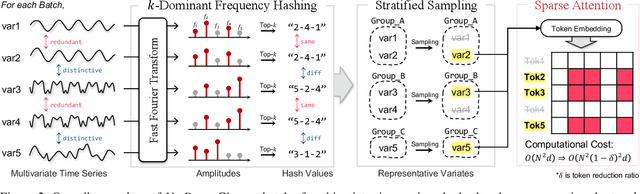
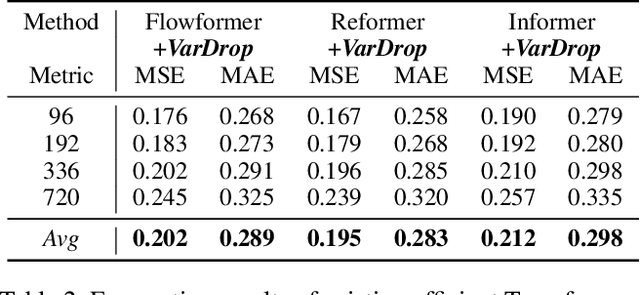
Variate tokenization, which independently embeds each variate as separate tokens, has achieved remarkable improvements in multivariate time series forecasting. However, employing self-attention with variate tokens incurs a quadratic computational cost with respect to the number of variates, thus limiting its training efficiency for large-scale applications. To address this issue, we propose VarDrop, a simple yet efficient strategy that reduces the token usage by omitting redundant variate tokens during training. VarDrop adaptively excludes redundant tokens within a given batch, thereby reducing the number of tokens used for dot-product attention while preserving essential information. Specifically, we introduce k-dominant frequency hashing (k-DFH), which utilizes the ranked dominant frequencies in the frequency domain as a hash value to efficiently group variate tokens exhibiting similar periodic behaviors. Then, only representative tokens in each group are sampled through stratified sampling. By performing sparse attention with these selected tokens, the computational cost of scaled dot-product attention is significantly alleviated. Experiments conducted on public benchmark datasets demonstrate that VarDrop outperforms existing efficient baselines.
Universal Time-Series Representation Learning: A Survey
Jan 08, 2024



Time-series data exists in every corner of real-world systems and services, ranging from satellites in the sky to wearable devices on human bodies. Learning representations by extracting and inferring valuable information from these time series is crucial for understanding the complex dynamics of particular phenomena and enabling informed decisions. With the learned representations, we can perform numerous downstream analyses more effectively. Among several approaches, deep learning has demonstrated remarkable performance in extracting hidden patterns and features from time-series data without manual feature engineering. This survey first presents a novel taxonomy based on three fundamental elements in designing state-of-the-art universal representation learning methods for time series. According to the proposed taxonomy, we comprehensively review existing studies and discuss their intuitions and insights into how these methods enhance the quality of learned representations. Finally, as a guideline for future studies, we summarize commonly used experimental setups and datasets and discuss several promising research directions. An up-to-date corresponding resource is available at https://github.com/itouchz/awesome-deep-time-series-representations.