 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
NASH: A Simple Unified Framework of Structured Pruning for Accelerating Encoder-Decoder Language Models
Oct 16, 2023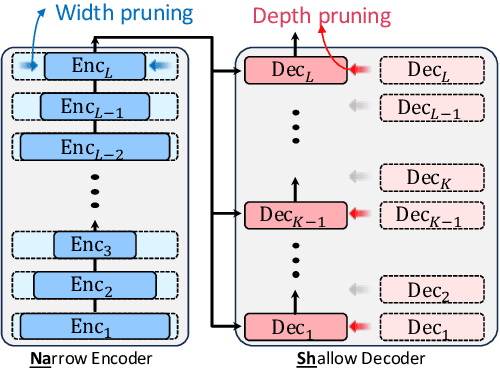


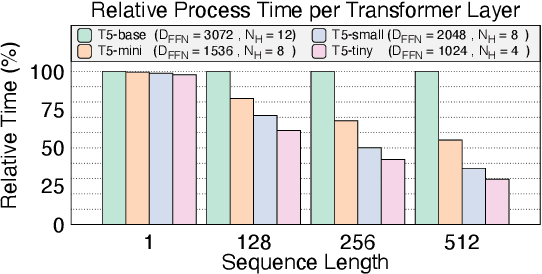
Structured pruning methods have proven effective in reducing the model size and accelerating inference speed in various network architectures such as Transformers. Despite the versatility of encoder-decoder models in numerous NLP tasks, the structured pruning methods on such models are relatively less explored compared to encoder-only models. In this study, we investigate the behavior of the structured pruning of the encoder-decoder models in the decoupled pruning perspective of the encoder and decoder component, respectively. Our findings highlight two insights: (1) the number of decoder layers is the dominant factor of inference speed, and (2) low sparsity in the pruned encoder network enhances generation quality. Motivated by these findings, we propose a simple and effective framework, NASH, that narrows the encoder and shortens the decoder networks of encoder-decoder models. Extensive experiments on diverse generation and inference tasks validate the effectiveness of our method in both speedup and output quality.
Revisiting Intermediate Layer Distillation for Compressing Language Models: An Overfitting Perspective
Feb 03, 2023



Knowledge distillation (KD) is a highly promising method for mitigating the computational problems of pre-trained language models (PLMs). Among various KD approaches, Intermediate Layer Distillation (ILD) has been a de facto standard KD method with its performance efficacy in the NLP field. In this paper, we find that existing ILD methods are prone to overfitting to training datasets, although these methods transfer more information than the original KD. Next, we present the simple observations to mitigate the overfitting of ILD: distilling only the last Transformer layer and conducting ILD on supplementary tasks. Based on our two findings, we propose a simple yet effective consistency-regularized ILD (CR-ILD), which prevents the student model from overfitting the training dataset. Substantial experiments on distilling BERT on the GLUE benchmark and several synthetic datasets demonstrate that our proposed ILD method outperforms other KD techniques. Our code is available at https://github.com/jongwooko/CR-ILD.