 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-Speech
Oct 04, 2024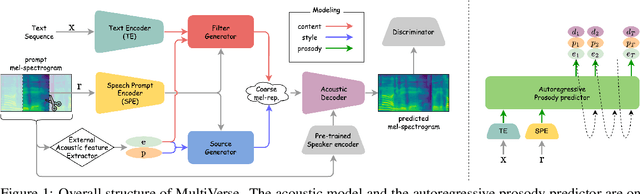
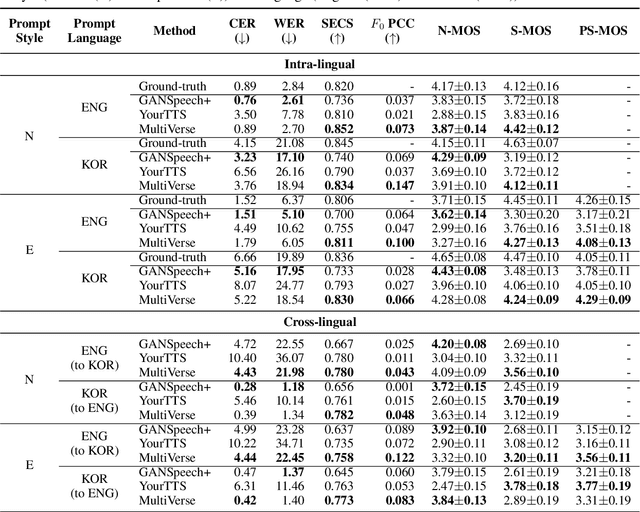


Text-to-speech (TTS) systems that scale up the amount of training data have achieved significant improvements in zero-shot speech synthesis. However, these systems have certain limitations: they require a large amount of training data, which increases costs, and often overlook prosody similarity. To address these issues, we propose MultiVerse, a zero-shot multi-task TTS system that is able to perform TTS or speech style transfer in zero-shot and cross-lingual conditions. MultiVerse requires much less training data than traditional data-driven approaches. To ensure zero-shot performance even with limited data, we leverage source-filter theory-based disentanglement, utilizing the prompt for modeling filter-related and source-related representations. Additionally, to further enhance prosody similarity, we adopt a prosody modeling approach combining prompt-based autoregressive and non-autoregressive methods. Evaluations demonstrate the remarkable zero-shot multi-task TTS performance of MultiVerse and show that MultiVerse not only achieves zero-shot TTS performance comparable to data-driven TTS systems with much less data, but also significantly outperforms other zero-shot TTS systems trained with the same small amount of data. In particular, our novel prosody modeling technique significantly contributes to MultiVerse's ability to generate speech with high prosody similarity to the given prompts. Our samples are available at https://nc-ai.github.io/speech/publications/multiverse/index.html
Anti-Spoofing Using Transfer Learning with Variational Information Bottleneck
Apr 04, 2022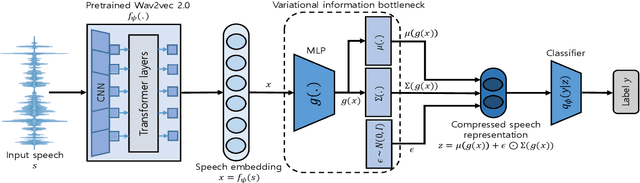
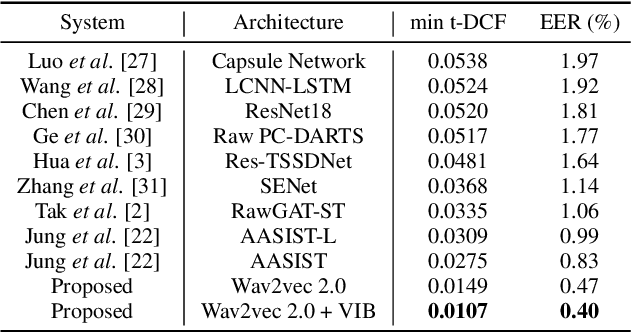
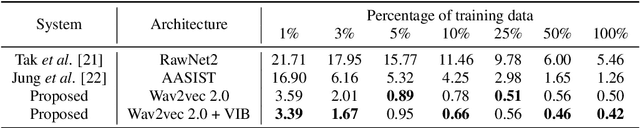
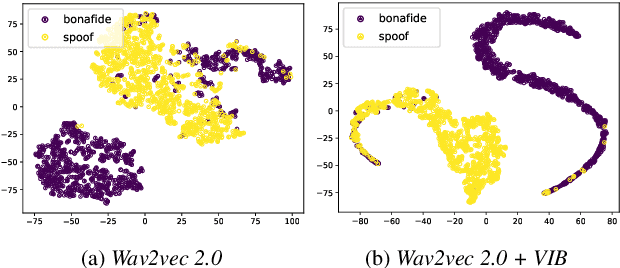
Recent advances in sophisticated synthetic speech generated from text-to-speech (TTS) or voice conversion (VC) systems cause threats to the existing automatic speaker verification (ASV) systems. Since such synthetic speech is generated from diverse algorithms, generalization ability with using limited training data is indispensable for a robust anti-spoofing system. In this work, we propose a transfer learning scheme based on the wav2vec 2.0 pretrained model with variational information bottleneck (VIB) for speech anti-spoofing task. Evaluation on the ASVspoof 2019 logical access (LA) database shows that our method improves the performance of distinguishing unseen spoofed and genuine speech, outperforming current state-of-the-art anti-spoofing systems. Furthermore, we show that the proposed system improves performance in low-resource and cross-dataset settings of anti-spoofing task significantly, demonstrating that our system is also robust in terms of data size and data distribution.