 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceLDM: Text-to-Speech with Environmental Context
Sep 24, 2023This paper presents VoiceLDM, a model designed to produce audio that accurately follows two distinct natural language text prompts: the description prompt and the content prompt. The former provides information about the overall environmental context of the audio, while the latter conveys the linguistic content. To achieve this, we adopt a text-to-audio (TTA) model based on latent diffusion models and extend its functionality to incorporate an additional content prompt as a conditional input. By utilizing pretrained contrastive language-audio pretraining (CLAP) and Whisper, VoiceLDM is trained on large amounts of real-world audio without manual annotations or transcriptions. Additionally, we employ dual classifier-free guidance to further enhance the controllability of VoiceLDM. Experimental results demonstrate that VoiceLDM is capable of generating plausible audio that aligns well with both input conditions, even surpassing the speech intelligibility of the ground truth audio on the AudioCaps test set. Furthermore, we explore the text-to-speech (TTS) and zero-shot text-to-audio capabilities of VoiceLDM and show that it achieves competitive results. Demos and code are available at https://voiceldm.github.io.
FitHuBERT: Going Thinner and Deeper for Knowledge Distillation of Speech Self-Supervised Learning
Jul 01, 2022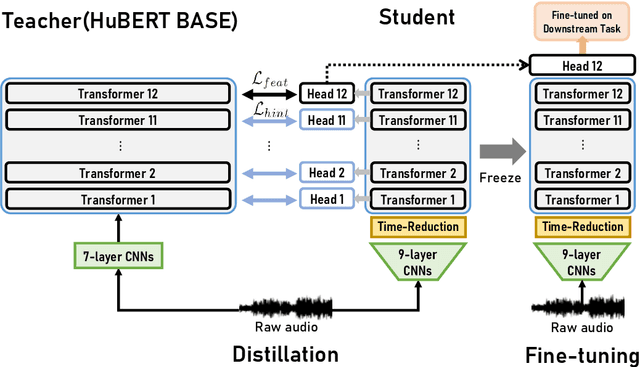
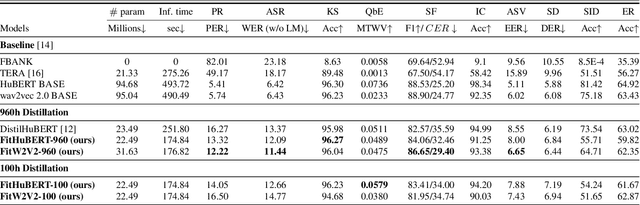
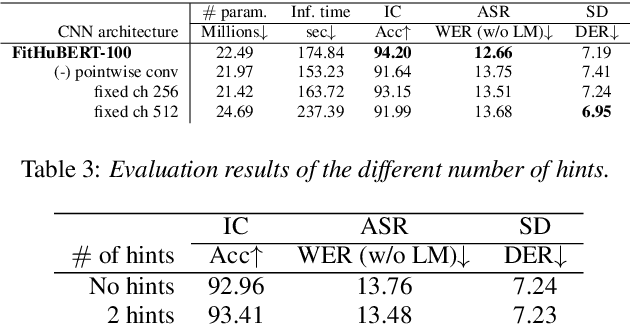

Large-scale speech self-supervised learning (SSL) has emerged to the main field of speech processing, however, the problem of computational cost arising from its vast size makes a high entry barrier to academia. In addition, existing distillation techniques of speech SSL models compress the model by reducing layers, which induces performance degradation in linguistic pattern recognition tasks such as phoneme recognition (PR). In this paper, we propose FitHuBERT, which makes thinner in dimension throughout almost all model components and deeper in layer compared to prior speech SSL distillation works. Moreover, we employ a time-reduction layer to speed up inference time and propose a method of hint-based distillation for less performance degradation. Our method reduces the model to 23.8% in size and 35.9% in inference time compared to HuBERT. Also, we achieve 12.1% word error rate and 13.3% phoneme error rate on the SUPERB benchmark which is superior than prior work.
Anti-Spoofing Using Transfer Learning with Variational Information Bottleneck
Apr 04, 2022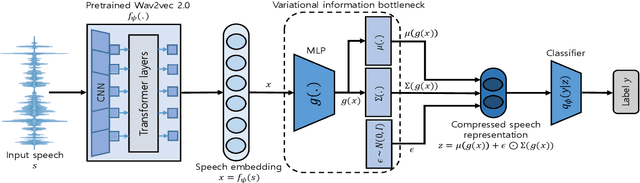
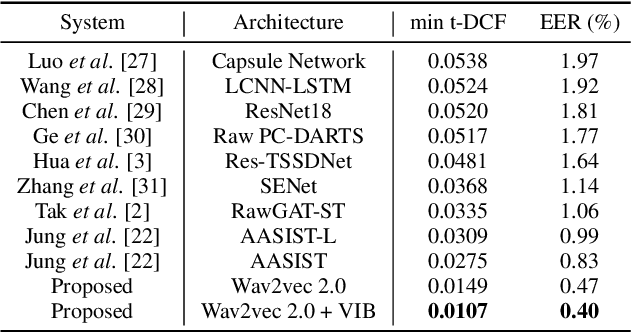
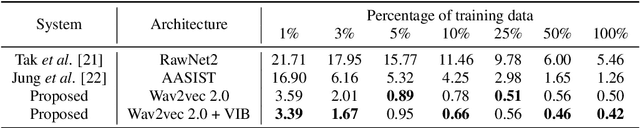
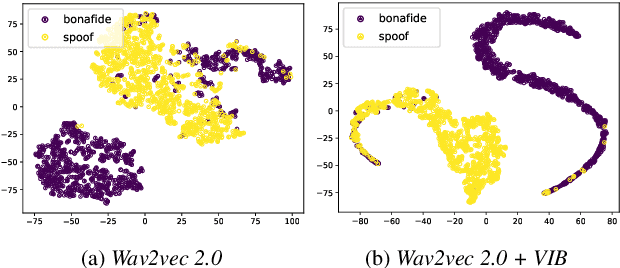
Recent advances in sophisticated synthetic speech generated from text-to-speech (TTS) or voice conversion (VC) systems cause threats to the existing automatic speaker verification (ASV) systems. Since such synthetic speech is generated from diverse algorithms, generalization ability with using limited training data is indispensable for a robust anti-spoofing system. In this work, we propose a transfer learning scheme based on the wav2vec 2.0 pretrained model with variational information bottleneck (VIB) for speech anti-spoofing task. Evaluation on the ASVspoof 2019 logical access (LA) database shows that our method improves the performance of distinguishing unseen spoofed and genuine speech, outperforming current state-of-the-art anti-spoofing systems. Furthermore, we show that the proposed system improves performance in low-resource and cross-dataset settings of anti-spoofing task significantly, demonstrating that our system is also robust in terms of data size and data distribution.