 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Do SSL Speech Models Listen for Tone? Temporal Focus of Tone Representation under Low-resource Transfer
Nov 15, 2025



Lexical tone is central to many languages but remains underexplored in self-supervised learning (SSL) speech models, especially beyond Mandarin. We study four languages with complex and diverse tone systems: Burmese, Thai, Lao, and Vietnamese, to examine how far such models listen for tone and how transfer operates in low-resource conditions. As a baseline reference, we estimate the temporal span of tone cues to be about 100 ms in Burmese and Thai, and about 180 ms in Lao and Vietnamese. Probes and gradient analyses on fine-tuned SSL models reveal that tone transfer varies by downstream task: automatic speech recognition fine-tuning aligns spans with language-specific tone cues, while prosody- and voice-related tasks bias the model toward overly long spans. These findings indicate that tone transfer is shaped by downstream task, highlighting task effects on temporal focus in tone modeling.
Anti-Spoofing Using Transfer Learning with Variational Information Bottleneck
Apr 04, 2022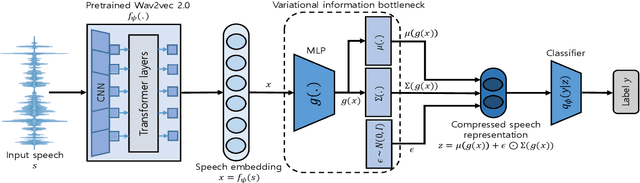
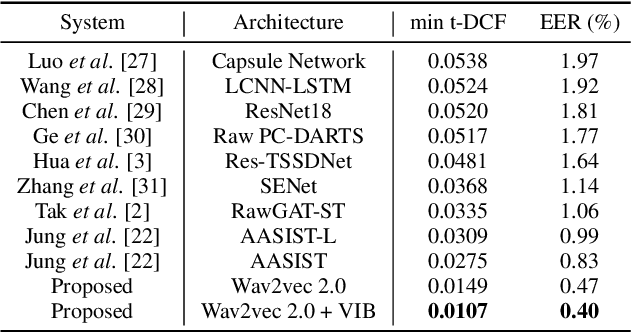
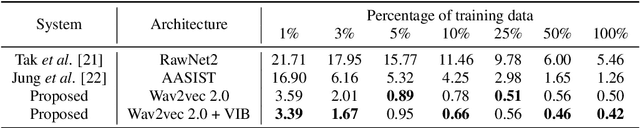
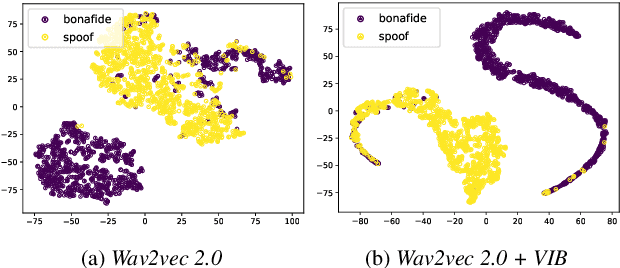
Recent advances in sophisticated synthetic speech generated from text-to-speech (TTS) or voice conversion (VC) systems cause threats to the existing automatic speaker verification (ASV) systems. Since such synthetic speech is generated from diverse algorithms, generalization ability with using limited training data is indispensable for a robust anti-spoofing system. In this work, we propose a transfer learning scheme based on the wav2vec 2.0 pretrained model with variational information bottleneck (VIB) for speech anti-spoofing task. Evaluation on the ASVspoof 2019 logical access (LA) database shows that our method improves the performance of distinguishing unseen spoofed and genuine speech, outperforming current state-of-the-art anti-spoofing systems. Furthermore, we show that the proposed system improves performance in low-resource and cross-dataset settings of anti-spoofing task significantly, demonstrating that our system is also robust in terms of data size and data distribution.