 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adaptive Soft Voice Activity Detection using Deep Neural Networks for Robust Speaker Verification
Paper and Code
Sep 26, 2019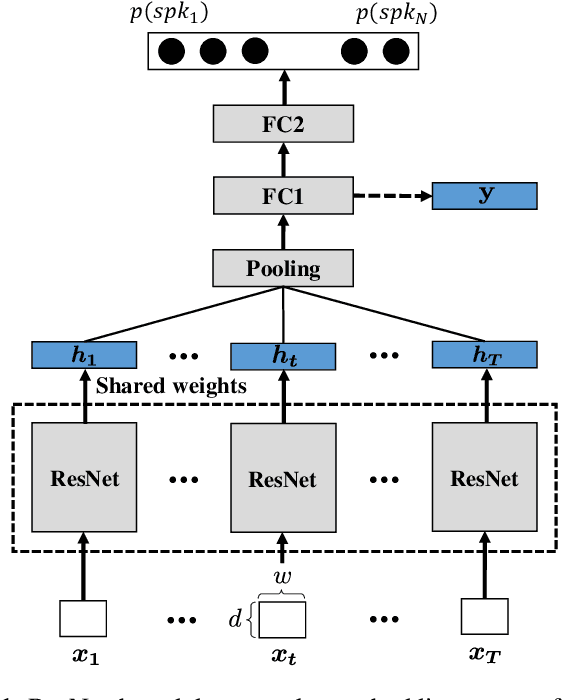


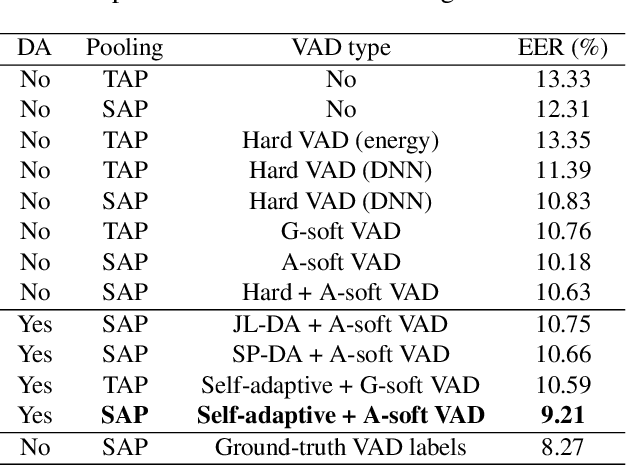
Voice activity detection (VAD), which classifies frames as speech or non-speech, is an important module in many speech applications including speaker verification. In this paper, we propose a novel method, called self-adaptive soft VAD, to incorporate a deep neural network (DNN)-based VAD into a deep speaker embedding system. The proposed method is a combination of the following two approaches. The first approach is soft VAD, which performs a soft selection of frame-level features extracted from a speaker feature extractor. The frame-level features are weighted by their corresponding speech posteriors estimated from the DNN-based VAD, and then aggregated to generate a speaker embedding. The second approach is self-adaptive VAD, which fine-tunes the pre-trained VAD on the speaker verification data to reduce the domain mismatch. Here, we introduce two unsupervised domain adaptation (DA) schemes, namely speech posterior-based DA (SP-DA) and joint learning-based DA (JL-DA). Experiments on a Korean speech database demonstrate that the verification performance is improved significantly in real-world environments by using self-adaptive soft VAD.