 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight feature encoder for wake-up word detection based on self-supervised speech representation
Mar 14, 2023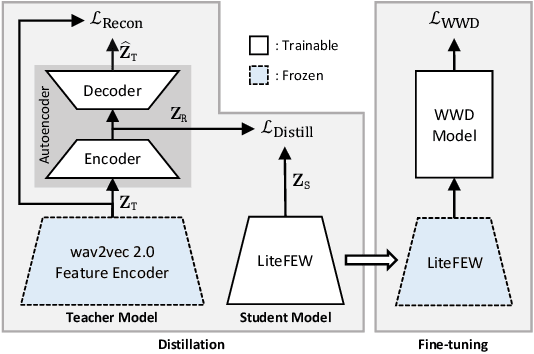



Self-supervised learning method that provides generalized speech representations has recently received increasing attention. Wav2vec 2.0 is the most famous example, showing remarkable performance in numerous downstream speech processing tasks. Despite its success, it is challenging to use it directly for wake-up word detection on mobile devices due to its expensive computational cost. In this work, we propose LiteFEW, a lightweight feature encoder for wake-up word detection that preserves the inherent ability of wav2vec 2.0 with a minimum scale. In the method, the knowledge of the pre-trained wav2vec 2.0 is compressed by introducing an auto-encoder-based dimensionality reduction technique and distilled to LiteFEW. Experimental results on the open-source "Hey Snips" dataset show that the proposed method applied to various model structures significantly improves the performance, achieving over 20% of relative improvements with only 64k parameters.
A Unified Deep Learning Framework for Short-Duration Speaker Verification in Adverse Environments
Oct 06, 2020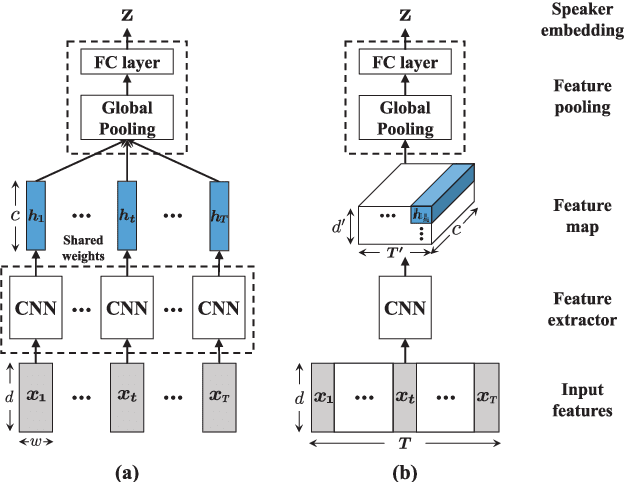
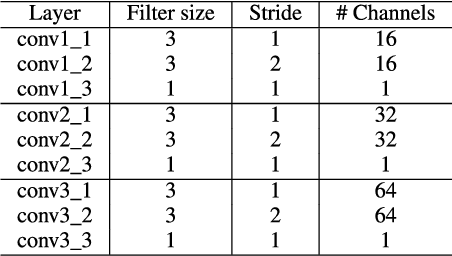
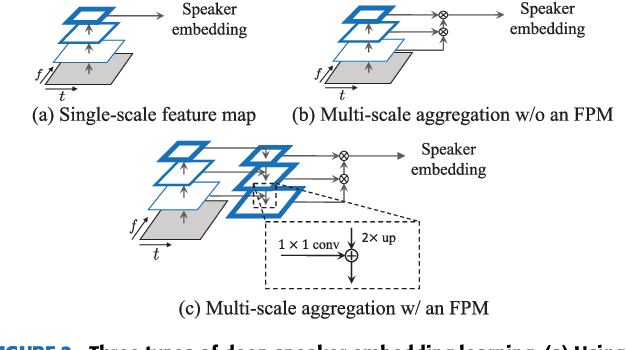
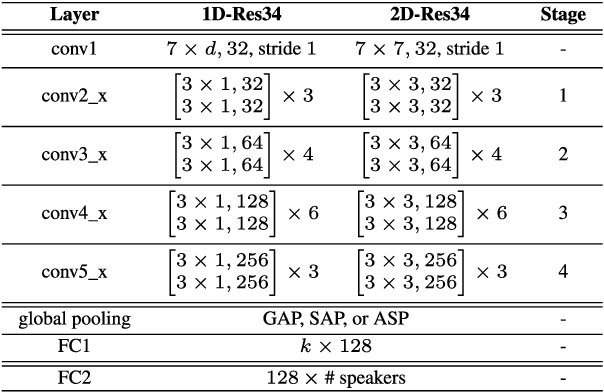
Speaker verification (SV) has recently attracted considerable research interest due to the growing popularity of virtual assistants. At the same time, there is an increasing requirement for an SV system: it should be robust to short speech segments, especially in noisy and reverberant environments. In this paper, we consider one more important requirement for practical applications: the system should be robust to an audio stream containing long non-speech segments, where a voice activity detection (VAD) is not applied. To meet these two requirements, we introduce feature pyramid module (FPM)-based multi-scale aggregation (MSA) and self-adaptive soft VAD (SAS-VAD). We present the FPM-based MSA to deal with short speech segments in noisy and reverberant environments. Also, we use the SAS-VAD to increase the robustness to long non-speech segments. To further improve the robustness to acoustic distortions (i.e., noise and reverberation), we apply a masking-based speech enhancement (SE) method. We combine SV, VAD, and SE models in a unified deep learning framework and jointly train the entire network in an end-to-end manner. To the best of our knowledge, this is the first work combining these three models in a deep learning framework. We conduct experiments on Korean indoor (KID) and VoxCeleb datasets, which are corrupted by noise and reverberation. The results show that the proposed method is effective for SV in the challenging conditions and performs better than the baseline i-vector and deep speaker embedding systems.
* 19 pages, 10 figures, 13 tables
Additional Shared Decoder on Siamese Multi-view Encoders for Learning Acoustic Word Embeddings
Oct 01, 2019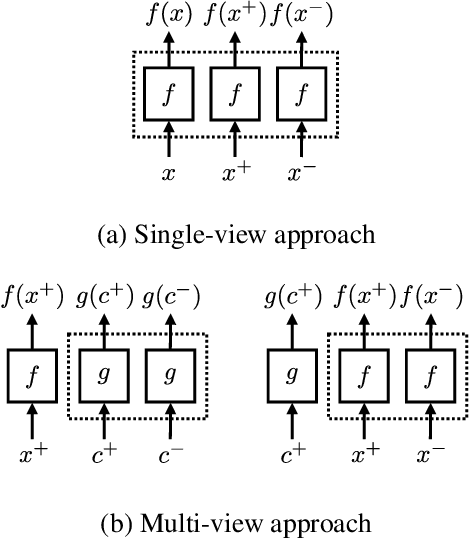
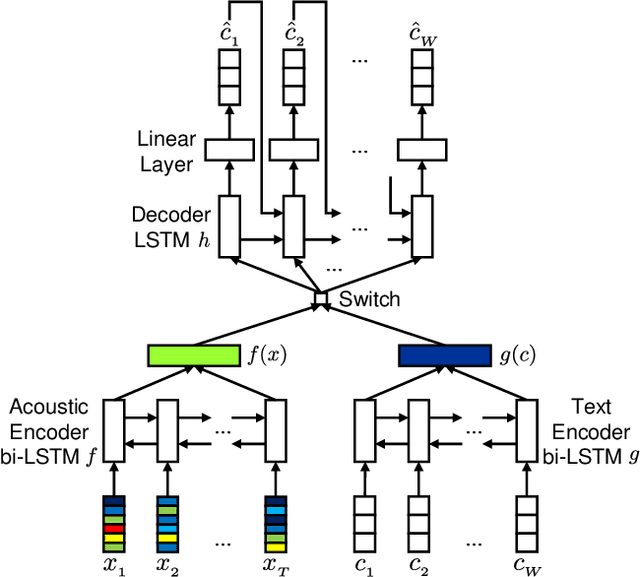
Acoustic word embeddings --- fixed-dimensional vector representations of arbitrary-length words --- have attracted increasing interest in query-by-example spoken term detection. Recently, on the fact that the orthography of text labels partly reflects the phonetic similarity between the words' pronunciation, a multi-view approach has been introduced that jointly learns acoustic and text embeddings. It showed that it is possible to learn discriminative embeddings by designing the objective which takes text labels as well as word segments. In this paper, we propose a network architecture that expands the multi-view approach by combining the Siamese multi-view encoders with a shared decoder network to maximize the effect of the relationship between acoustic and text embeddings in embedding space. Discriminatively trained with multi-view triplet loss and decoding loss, our proposed approach achieves better performance on acoustic word discrimination task with the WSJ dataset, resulting in 11.1% relative improvement in average precision. We also present experimental results on cross-view word discrimination and word level speech recognition tasks.
Spatial Pyramid Encoding with Convex Length Normalization for Text-Independent Speaker Verification
Jun 19, 2019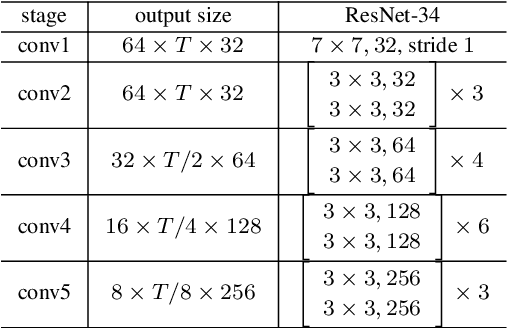
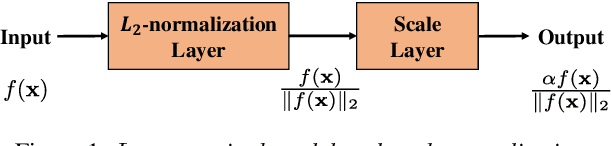
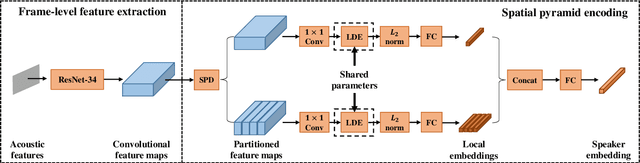
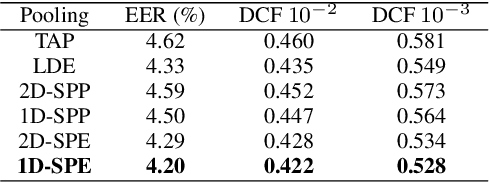
In this paper, we propose a new pooling method called spatial pyramid encoding (SPE) to generate speaker embeddings for text-independent speaker verification. We first partition the output feature maps from a deep residual network (ResNet) into increasingly fine sub-regions and extract speaker embeddings from each sub-region through a learnable dictionary encoding layer. These embeddings are concatenated to obtain the final speaker representation. The SPE layer not only generates a fixed-dimensional speaker embedding for a variable-length speech segment, but also aggregates the information of feature distribution from multi-level temporal bins. Furthermore, we apply deep length normalization by augmenting the loss function with ring loss. By applying ring loss, the network gradually learns to normalize the speaker embeddings using model weights themselves while preserving convexity, leading to more robust speaker embeddings. Experiments on the VoxCeleb1 dataset show that the proposed system using the SPE layer and ring loss-based deep length normalization outperforms both i-vector and d-vector baselines.
Learning acoustic word embeddings with phonetically associated triplet network
Nov 28, 2018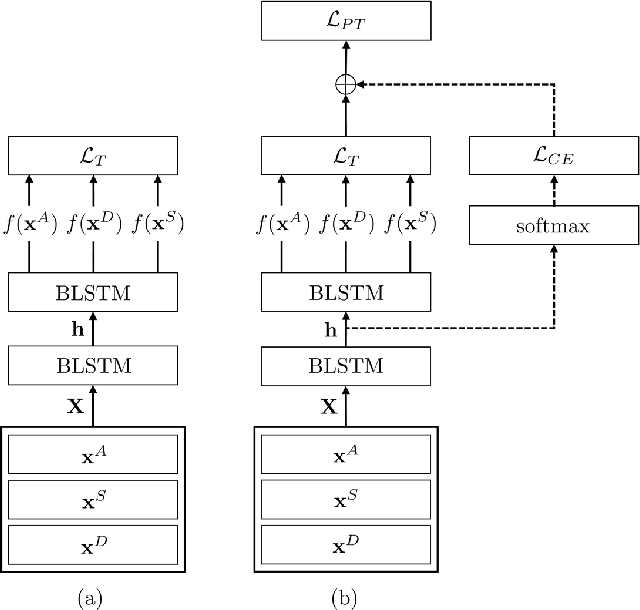

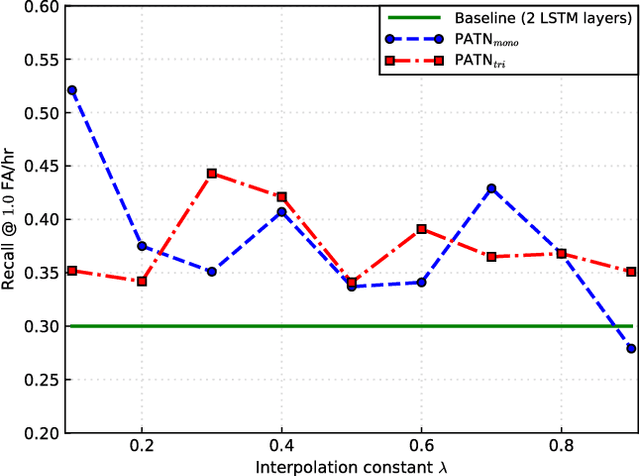

Previous researches on acoustic word embeddings used in query-by-example spoken term detection have shown remarkable performance improvements when using a triplet network. However, the triplet network is trained using only a limited information about acoustic similarity between words. In this paper, we propose a novel architecture, phonetically associated triplet network (PATN), which aims at increasing discriminative power of acoustic word embeddings by utilizing phonetic information as well as word identity. The proposed model is learned to minimize a combined loss function that was made by introducing a cross entropy loss to the lower layer of LSTM-based triplet network. We observed that the proposed method performs significantly better than the baseline triplet network on a word discrimination task with the WSJ dataset resulting in over 20% relative improvement in recall rate at 1.0 false alarm per hour. Finally, we examined the generalization ability by conducting the out-of-domain test on the RM dataset.