 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning acoustic word embeddings with phonetically associated triplet network
Paper and Code
Nov 28, 2018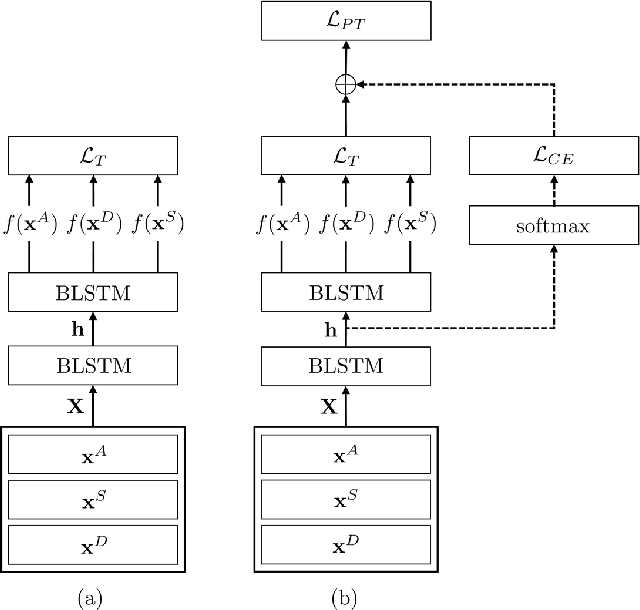

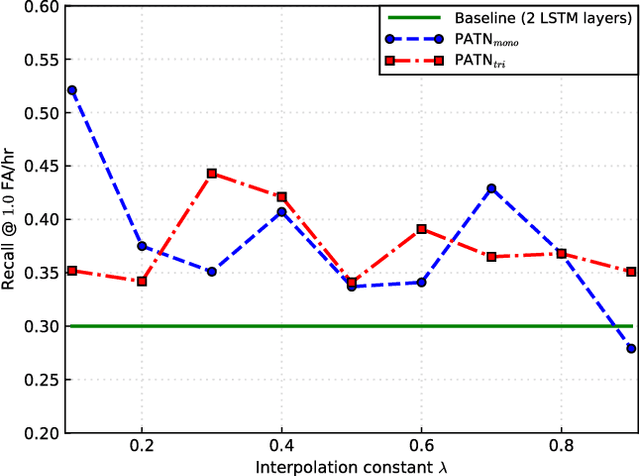

Previous researches on acoustic word embeddings used in query-by-example spoken term detection have shown remarkable performance improvements when using a triplet network. However, the triplet network is trained using only a limited information about acoustic similarity between words. In this paper, we propose a novel architecture, phonetically associated triplet network (PATN), which aims at increasing discriminative power of acoustic word embeddings by utilizing phonetic information as well as word identity. The proposed model is learned to minimize a combined loss function that was made by introducing a cross entropy loss to the lower layer of LSTM-based triplet network. We observed that the proposed method performs significantly better than the baseline triplet network on a word discrimination task with the WSJ dataset resulting in over 20% relative improvement in recall rate at 1.0 false alarm per hour. Finally, we examined the generalization ability by conducting the out-of-domain test on the RM dataset.