 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled representation learning for multilingual speaker recognition
Paper and Code
Nov 01, 2022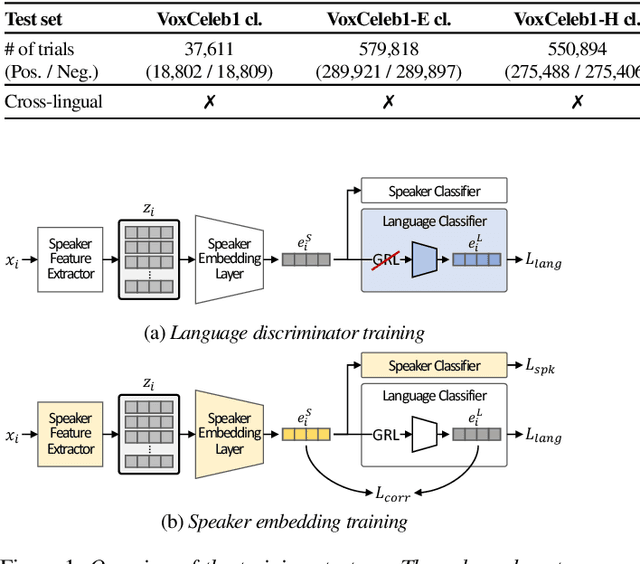

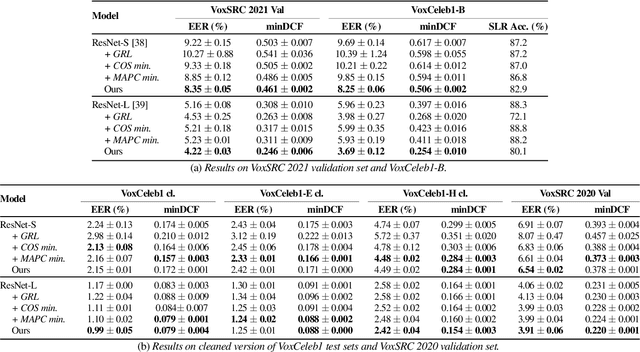
The goal of this paper is to train speaker embeddings that are robust to bilingual speaking scenario. The majority of the world's population speak at least two languages; however, most speaker recognition systems fail to recognise the same speaker when speaking in different languages. Popular speaker recognition evaluation sets do not consider the bilingual scenario, making it difficult to analyse the effect of bilingual speakers on speaker recognition performance. This paper proposes a new large-scale evaluation set derived from VoxCeleb that considers bilingual scenarios. We also introduce a representation learning strategy, which disentangles language information from speaker representation to account for the bilingual scenario. This language-disentangled representation learning strategy can be adapted to existing models with small changes to the training pipeline. Experimental results demonstrate that the baseline models suffer significant performance degradation when evaluated on the proposed bilingual test set. On the contrary, the model trained with the proposed disentanglement strategy shows significant improvement under the bilingual evaluation scenario while simultaneously retaining competitive performance on existing monolingual test sets.