 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Stochastic Optimization of a Neural Representation Network for Time-Space Tomography Reconstruction
Apr 29, 2024



4D time-space reconstruction of dynamic events or deforming objects using X-ray computed tomography (CT) is an extremely ill-posed inverse problem. Existing approaches assume that the object remains static for the duration of several tens or hundreds of X-ray projection measurement images (reconstruction of consecutive limited-angle CT scans). However, this is an unrealistic assumption for many in-situ experiments that causes spurious artifacts and inaccurate morphological reconstructions of the object. To solve this problem, we propose to perform a 4D time-space reconstruction using a distributed implicit neural representation (DINR) network that is trained using a novel distributed stochastic training algorithm. Our DINR network learns to reconstruct the object at its output by iterative optimization of its network parameters such that the measured projection images best match the output of the CT forward measurement model. We use a continuous time and space forward measurement model that is a function of the DINR outputs at a sparsely sampled set of continuous valued object coordinates. Unlike existing state-of-the-art neural representation architectures that forward and back propagate through dense voxel grids that sample the object's entire time-space coordinates, we only propagate through the DINR at a small subset of object coordinates in each iteration resulting in an order-of-magnitude reduction in memory and compute for training. DINR leverages distributed computation across several compute nodes and GPUs to produce high-fidelity 4D time-space reconstructions even for extremely large CT data sizes. We use both simulated parallel-beam and experimental cone-beam X-ray CT datasets to demonstrate the superior performance of our approach.
Non-Linear Phase-Retrieval Algorithms for X-ray Propagation-Based Phase-Contrast Tomography
Apr 29, 2023X-ray phase-contrast tomography (XPCT) is widely used for high-contrast 3D micron-scale imaging using nearly monochromatic X-rays at synchrotron beamlines. XPCT enables an order of magnitude improvement in image contrast of the reconstructed material interfaces with low X-ray absorption contrast. The dominant approaches to 3D reconstruction using XPCT relies on the use of phase-retrieval algorithms that make one or more limiting approximations for the experimental configuration and material properties. Since many experimental scenarios violate such approximations, the resulting reconstructions contain blur, artifacts, or other quantitative inaccuracies. Our solution to this problem is to formulate new iterative non-linear phase-retrieval (NLPR) algorithms that avoid such limiting approximations. Compared to the widely used state-of-the-art approaches, we show that our proposed algorithms result in sharp and quantitatively accurate reconstruction with reduced artifacts. Unlike existing NLPR algorithms, our approaches avoid the laborious manual tuning of regularization hyper-parameters while still achieving the stated goals. As an alternative to regularization, we propose explicit constraints on the material properties to constrain the solution space and solve the phase-retrieval problem. These constraints are easily user-configurable since they follow directly from the imaged object's dimensions and material properties.
X-ray Spectral Estimation using Dictionary Learning
Feb 27, 2023As computational tools for X-ray computed tomography (CT) become more quantitatively accurate, knowledge of the source-detector spectral response is critical for quantitative system-independent reconstruction and material characterization capabilities. Directly measuring the spectral response of a CT system is hard, which motivates spectral estimation using transmission data obtained from a collection of known homogeneous objects. However, the associated inverse problem is ill-conditioned, making accurate estimation of the spectrum challenging, particularly in the absence of a close initial guess. In this paper, we describe a dictionary-based spectral estimation method that yields accurate results without the need for any initial estimate of the spectral response. Our method utilizes a MAP estimation framework that combines a physics-based forward model along with an $L_0$ sparsity constraint and a simplex constraint on the dictionary coefficients. Our method uses a greedy support selection method and a new pair-wise iterated coordinate descent method to compute the above estimate. We demonstrate that our dictionary-based method outperforms a state-of-the-art method as shown in a cross-validation experiment on four real datasets collected at beamline 8.3.2 of the Advanced Light Source (ALS).
DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
Nov 22, 2022Limited-Angle Computed Tomography (LACT) is a non-destructive evaluation technique used in a variety of applications ranging from security to medicine. The limited angle coverage in LACT is often a dominant source of severe artifacts in the reconstructed images, making it a challenging inverse problem. We present DOLCE, a new deep model-based framework for LACT that uses a conditional diffusion model as an image prior. Diffusion models are a recent class of deep generative models that are relatively easy to train due to their implementation as image denoisers. DOLCE can form high-quality images from severely under-sampled data by integrating data-consistency updates with the sampling updates of a diffusion model, which is conditioned on the transformed limited-angle data. We show through extensive experimentation on several challenging real LACT datasets that, the same pre-trained DOLCE model achieves the SOTA performance on drastically different types of images. Additionally, we show that, unlike standard LACT reconstruction methods, DOLCE naturally enables the quantification of the reconstruction uncertainty by generating multiple samples consistent with the measured data.
Dynamic CT Reconstruction from Limited Views with Implicit Neural Representations and Parametric Motion Fields
Apr 23, 2021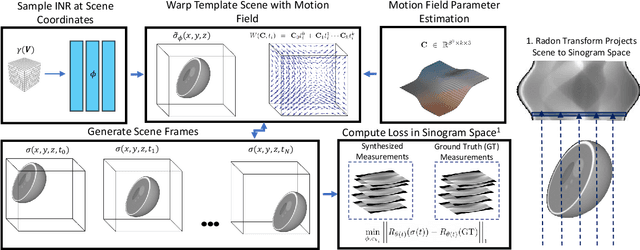
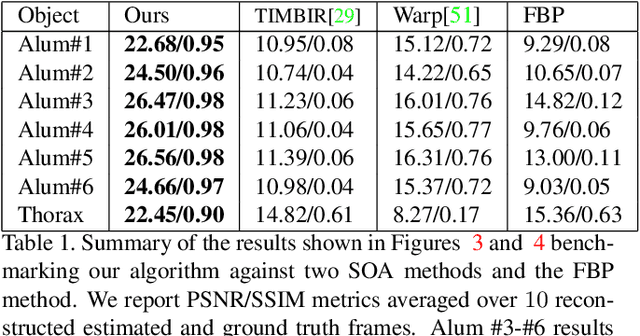
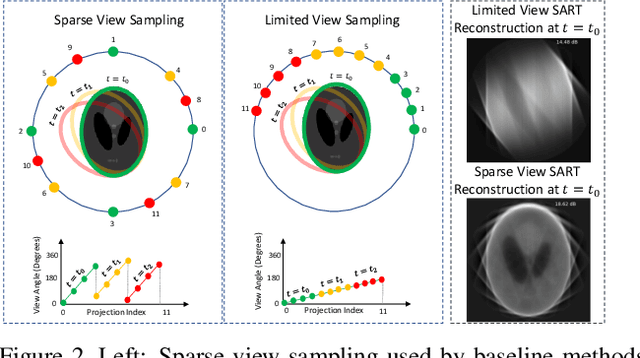

Reconstructing dynamic, time-varying scenes with computed tomography (4D-CT) is a challenging and ill-posed problem common to industrial and medical settings. Existing 4D-CT reconstructions are designed for sparse sampling schemes that require fast CT scanners to capture multiple, rapid revolutions around the scene in order to generate high quality results. However, if the scene is moving too fast, then the sampling occurs along a limited view and is difficult to reconstruct due to spatiotemporal ambiguities. In this work, we design a reconstruction pipeline using implicit neural representations coupled with a novel parametric motion field warping to perform limited view 4D-CT reconstruction of rapidly deforming scenes. Importantly, we utilize a differentiable analysis-by-synthesis approach to compare with captured x-ray sinogram data in a self-supervised fashion. Thus, our resulting optimization method requires no training data to reconstruct the scene. We demonstrate that our proposed system robustly reconstructs scenes containing deformable and periodic motion and validate against state-of-the-art baselines. Further, we demonstrate an ability to reconstruct continuous spatiotemporal representations of our scenes and upsample them to arbitrary volumes and frame rates post-optimization. This research opens a new avenue for implicit neural representations in computed tomography reconstruction in general.
Algorithm-driven Advances for Scientific CT Instruments: From Model-based to Deep Learning-based Approaches
Apr 16, 2021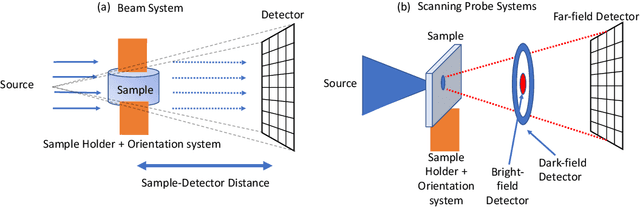
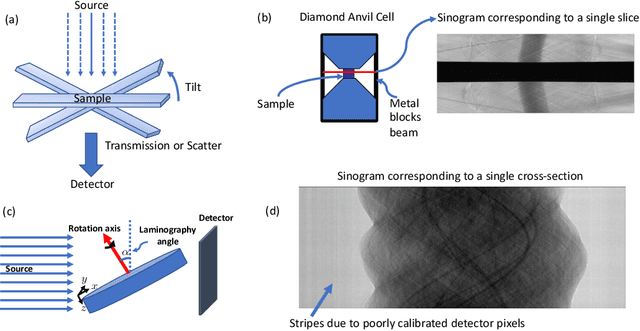
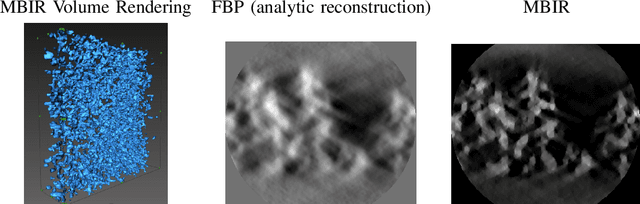
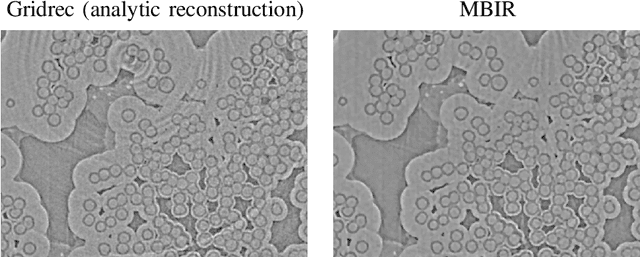
Multi-scale 3D characterization is widely used by materials scientists to further their understanding of the relationships between microscopic structure and macroscopic function. Scientific computed tomography (CT) instruments are one of the most popular choices for 3D non-destructive characterization of materials at length scales ranging from the angstrom-scale to the micron-scale. These instruments typically have a source of radiation that interacts with the sample to be studied and a detector assembly to capture the result of this interaction. A collection of such high-resolution measurements are made by re-orienting the sample which is mounted on a specially designed stage/holder after which reconstruction algorithms are used to produce the final 3D volume of interest. The end goal of scientific CT scans include determining the morphology,chemical composition or dynamic behavior of materials when subjected to external stimuli. In this article, we will present an overview of recent advances in reconstruction algorithms that have enabled significant improvements in the performance of scientific CT instruments - enabling faster, more accurate and novel imaging capabilities. In the first part, we will focus on model-based image reconstruction algorithms that formulate the inversion as solving a high-dimensional optimization problem involving a data-fidelity term and a regularization term. In the last part of the article, we will present an overview of recent approaches using deep-learning based algorithms for improving scientific CT instruments.
Mixture Model Framework for Traumatic Brain Injury Prognosis Using Heterogeneous Clinical and Outcome Data
Dec 22, 2020



Prognoses of Traumatic Brain Injury (TBI) outcomes are neither easily nor accurately determined from clinical indicators. This is due in part to the heterogeneity of damage inflicted to the brain, ultimately resulting in diverse and complex outcomes. Using a data-driven approach on many distinct data elements may be necessary to describe this large set of outcomes and thereby robustly depict the nuanced differences among TBI patients' recovery. In this work, we develop a method for modeling large heterogeneous data types relevant to TBI. Our approach is geared toward the probabilistic representation of mixed continuous and discrete variables with missing values. The model is trained on a dataset encompassing a variety of data types, including demographics, blood-based biomarkers, and imaging findings. In addition, it includes a set of clinical outcome assessments at 3, 6, and 12 months post-injury. The model is used to stratify patients into distinct groups in an unsupervised learning setting. We use the model to infer outcomes using input data, and show that the collection of input data reduces uncertainty of outcomes over a baseline approach. In addition, we quantify the performance of a likelihood scoring technique that can be used to self-evaluate confidence in model fit and prediction.
AutoAtlas: Neural Network for 3D Unsupervised Partitioning and Representation Learning
Nov 05, 2020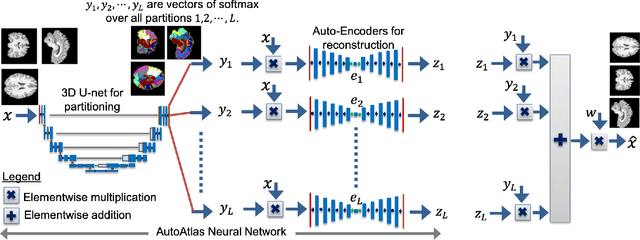
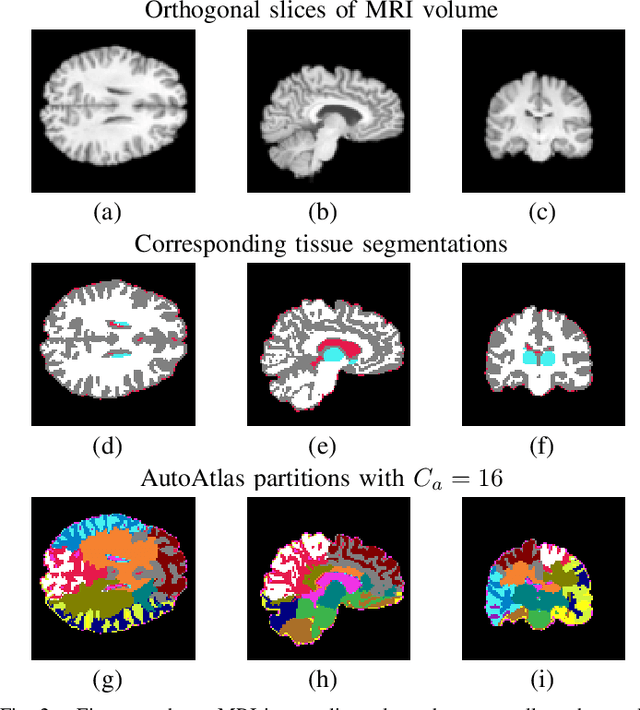

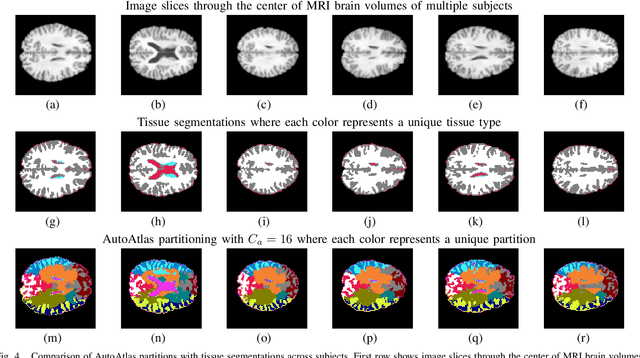
We present a novel neural network architecture called AutoAtlas for fully unsupervised partitioning and representation learning of 3D brain Magnetic Resonance Imaging (MRI) volumes. AutoAtlas consists of two neural network components: one that performs multi-label partitioning based on local texture in the volume and a second that compresses the information contained within each partition. We train both of these components simultaneously by optimizing a loss function that is designed to promote accurate reconstruction of each partition, while encouraging spatially smooth and contiguous partitioning, and discouraging relatively small partitions. We show that the partitions adapt to the subject specific structural variations of brain tissue while consistently appearing at similar spatial locations across subjects. AutoAtlas also produces very low dimensional features that represent local texture of each partition. We demonstrate prediction of metadata associated with each subject using the derived feature representations and compare the results to prediction using features derived from FreeSurfer anatomical parcellation. Since our features are intrinsically linked to distinct partitions, we can then map values of interest, such as partition-specific feature importance scores onto the brain for visualization.
Improving Limited Angle CT Reconstruction with a Robust GAN Prior
Oct 14, 2019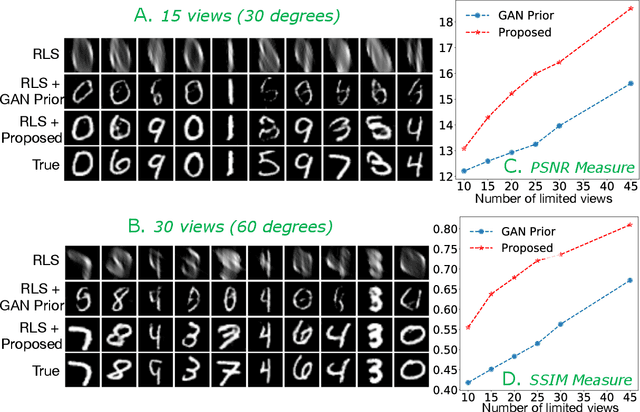
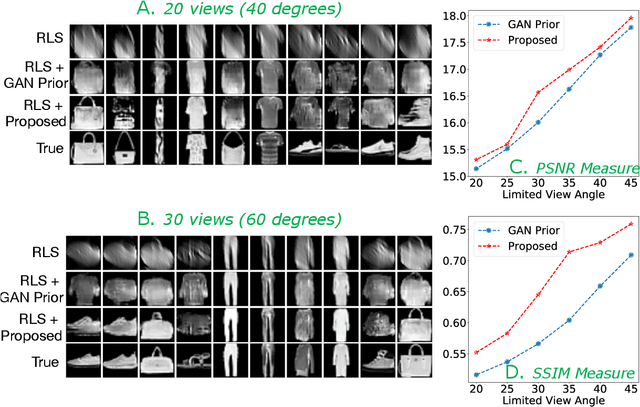
Limited angle CT reconstruction is an under-determined linear inverse problem that requires appropriate regularization techniques to be solved. In this work we study how pre-trained generative adversarial networks (GANs) can be used to clean noisy, highly artifact laden reconstructions from conventional techniques, by effectively projecting onto the inferred image manifold. In particular, we use a robust version of the popularly used GAN prior for inverse problems, based on a recent technique called corruption mimicking, that significantly improves the reconstruction quality. The proposed approach operates in the image space directly, as a result of which it does not need to be trained or require access to the measurement model, is scanner agnostic, and can work over a wide range of sensing scenarios.
Extreme Few-view CT Reconstruction using Deep Inference
Oct 11, 2019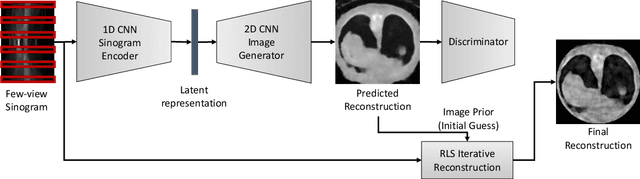

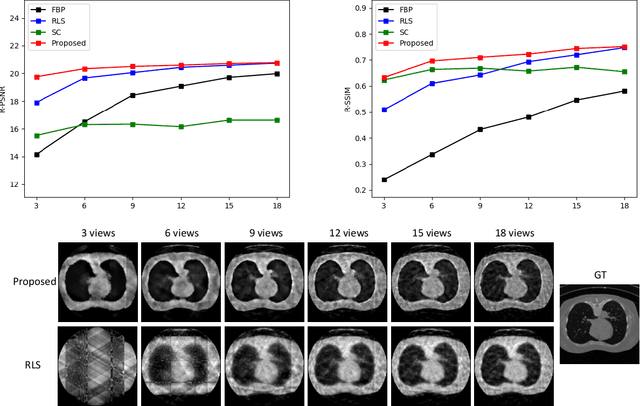
Reconstruction of few-view x-ray Computed Tomography (CT) data is a highly ill-posed problem. It is often used in applications that require low radiation dose in clinical CT, rapid industrial scanning, or fixed-gantry CT. Existing analytic or iterative algorithms generally produce poorly reconstructed images, severely deteriorated by artifacts and noise, especially when the number of x-ray projections is considerably low. This paper presents a deep network-driven approach to address extreme few-view CT by incorporating convolutional neural network-based inference into state-of-the-art iterative reconstruction. The proposed method interprets few-view sinogram data using attention-based deep networks to infer the reconstructed image. The predicted image is then used as prior knowledge in the iterative algorithm for final reconstruction. We demonstrate effectiveness of the proposed approach by performing reconstruction experiments on a chest CT dataset.