 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Audio Segmentation for Long-form Speech Translation
Jun 15, 2024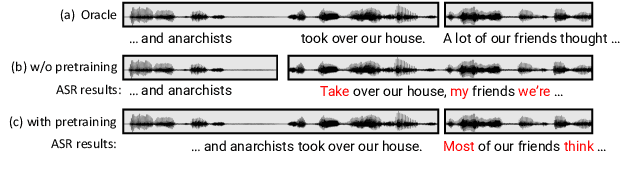
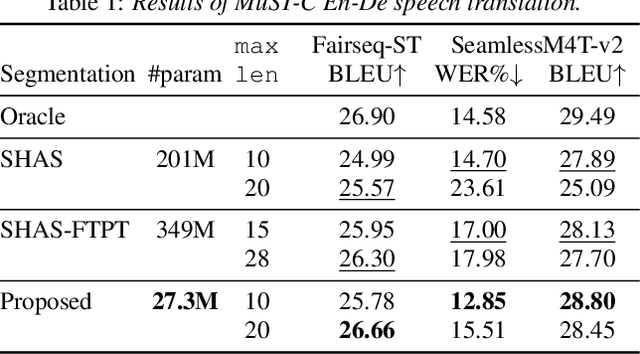

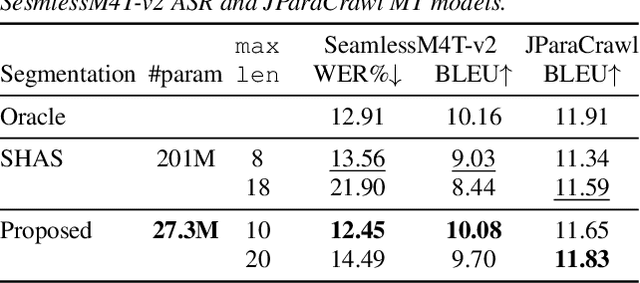
Speech segmentation is an essential part of speech translation (ST) systems in real-world scenarios. Since most ST models are designed to process speech segments, long-form audio must be partitioned into shorter segments before translation. Recently, data-driven approaches for the speech segmentation task have been developed. Although the approaches improve overall translation quality, a performance gap exists due to a mismatch between the models and ST systems. In addition, the prior works require large self-supervised speech models, which consume significant computational resources. In this work, we propose a segmentation model that achieves better speech translation quality with a small model size. We propose an ASR-with-punctuation task as an effective pre-training strategy for the segmentation model. We also show that proper integration of the speech segmentation model into the underlying ST system is critical to improve overall translation quality at inference time.
I3D: Transformer architectures with input-dependent dynamic depth for speech recognition
Mar 14, 2023Transformer-based end-to-end speech recognition has achieved great success. However, the large footprint and computational overhead make it difficult to deploy these models in some real-world applications. Model compression techniques can reduce the model size and speed up inference, but the compressed model has a fixed architecture which might be suboptimal. We propose a novel Transformer encoder with Input-Dependent Dynamic Depth (I3D) to achieve strong performance-efficiency trade-offs. With a similar number of layers at inference time, I3D-based models outperform the vanilla Transformer and the static pruned model via iterative layer pruning. We also present interesting analysis on the gate probabilities and the input-dependency, which helps us better understand deep encoders.
Better Intermediates Improve CTC Inference
Apr 01, 2022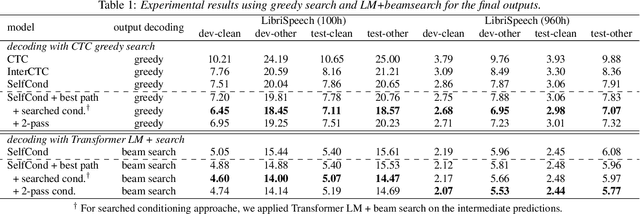

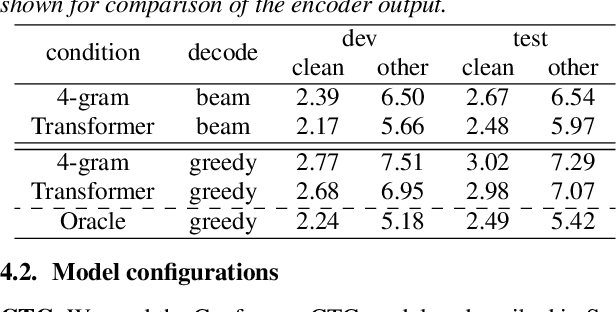
This paper proposes a method for improved CTC inference with searched intermediates and multi-pass conditioning. The paper first formulates self-conditioned CTC as a probabilistic model with an intermediate prediction as a latent representation and provides a tractable conditioning framework. We then propose two new conditioning methods based on the new formulation: (1) Searched intermediate conditioning that refines intermediate predictions with beam-search, (2) Multi-pass conditioning that uses predictions of previous inference for conditioning the next inference. These new approaches enable better conditioning than the original self-conditioned CTC during inference and improve the final performance. Experiments with the LibriSpeech dataset show relative 3%/12% performance improvement at the maximum in test clean/other sets compared to the original self-conditioned CTC.
Memory-Efficient Training of RNN-Transducer with Sampled Softmax
Mar 31, 2022
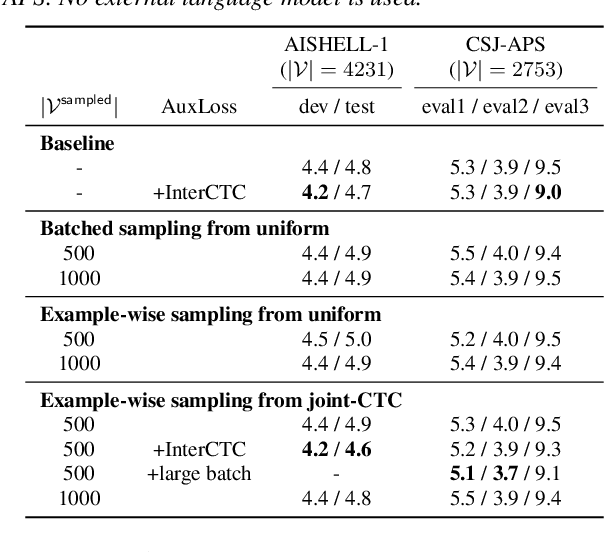
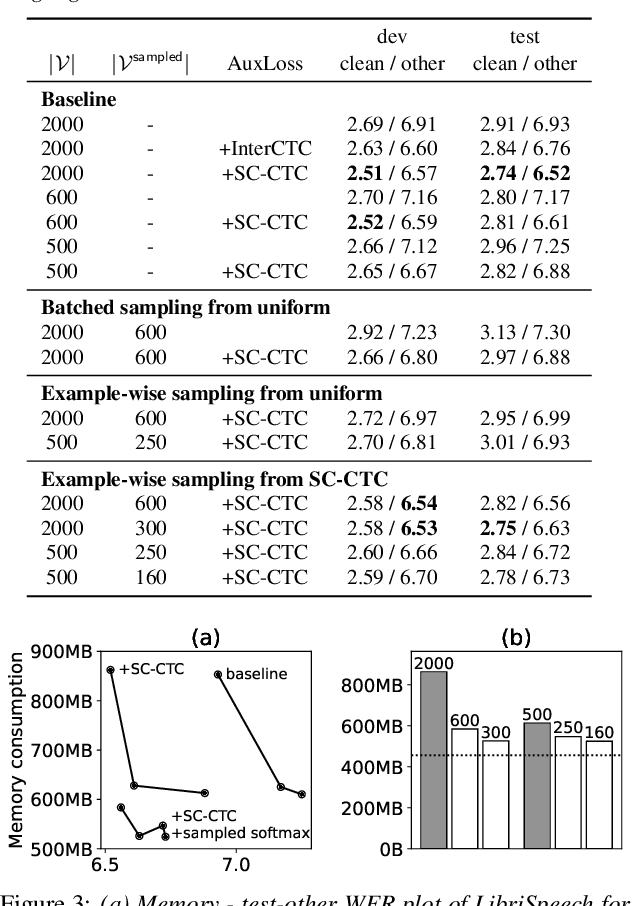
RNN-Transducer has been one of promising architectures for end-to-end automatic speech recognition. Although RNN-Transducer has many advantages including its strong accuracy and streaming-friendly property, its high memory consumption during training has been a critical problem for development. In this work, we propose to apply sampled softmax to RNN-Transducer, which requires only a small subset of vocabulary during training thus saves its memory consumption. We further extend sampled softmax to optimize memory consumption for a minibatch, and employ distributions of auxiliary CTC losses for sampling vocabulary to improve model accuracy. We present experimental results on LibriSpeech, AISHELL-1, and CSJ-APS, where sampled softmax greatly reduces memory consumption and still maintains the accuracy of the baseline model.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021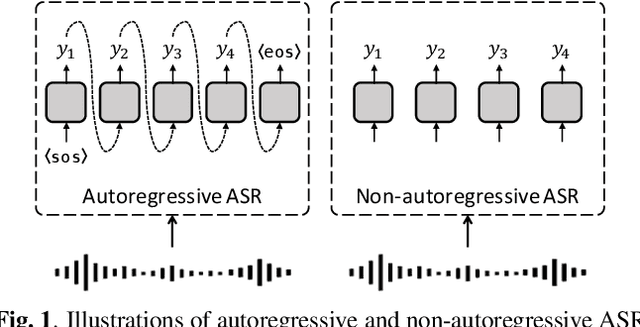

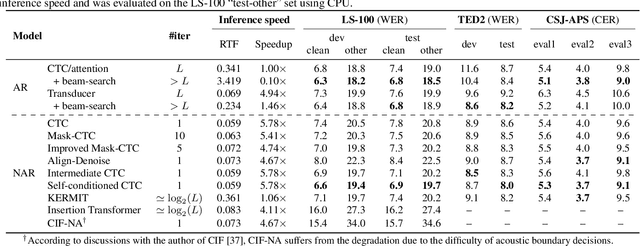
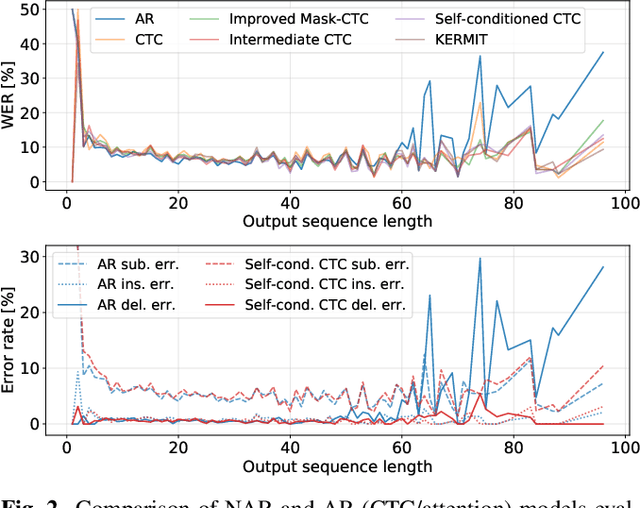
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Layer Pruning on Demand with Intermediate CTC
Jun 17, 2021
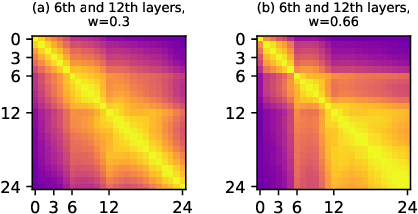
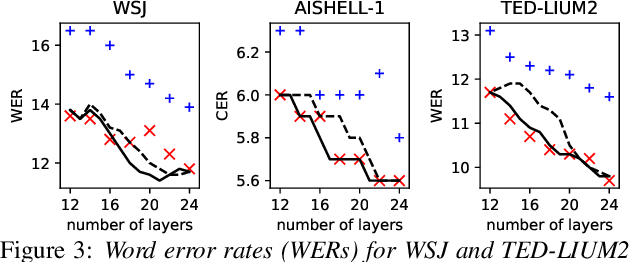
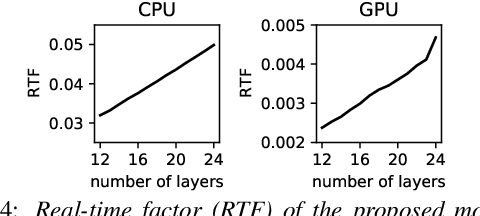
Deploying an end-to-end automatic speech recognition (ASR) model on mobile/embedded devices is a challenging task, since the device computational power and energy consumption requirements are dynamically changed in practice. To overcome the issue, we present a training and pruning method for ASR based on the connectionist temporal classification (CTC) which allows reduction of model depth at run-time without any extra fine-tuning. To achieve the goal, we adopt two regularization methods, intermediate CTC and stochastic depth, to train a model whose performance does not degrade much after pruning. We present an in-depth analysis of layer behaviors using singular vector canonical correlation analysis (SVCCA), and efficient strategies for finding layers which are safe to prune. Using the proposed method, we show that a Transformer-CTC model can be pruned in various depth on demand, improving real-time factor from 0.005 to 0.002 on GPU, while each pruned sub-model maintains the accuracy of individually trained model of the same depth.
Intermediate Loss Regularization for CTC-based Speech Recognition
Feb 05, 2021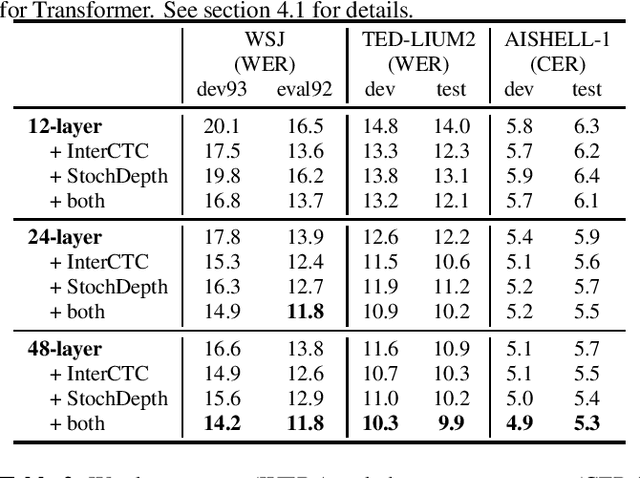

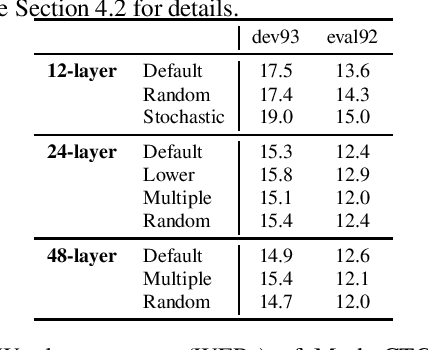
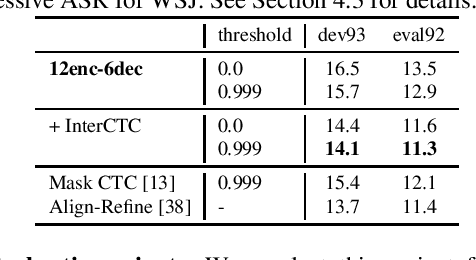
We present a simple and efficient auxiliary loss function for automatic speech recognition (ASR) based on the connectionist temporal classification (CTC) objective. The proposed objective, an intermediate CTC loss, is attached to an intermediate layer in the CTC encoder network. This intermediate CTC loss well regularizes CTC training and improves the performance requiring only small modification of the code and small and no overhead during training and inference, respectively. In addition, we propose to combine this intermediate CTC loss with stochastic depth training, and apply this combination to a recently proposed Conformer network. We evaluate the proposed method on various corpora, reaching word error rate (WER) 9.9% on the WSJ corpus and character error rate (CER) 5.2% on the AISHELL-1 corpus respectively, based on CTC greedy search without a language model. Especially, the AISHELL-1 task is comparable to other state-of-the-art ASR systems based on auto-regressive decoder with beam search.