 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Audio Segmentation for Long-form Speech Translation
Paper and Code
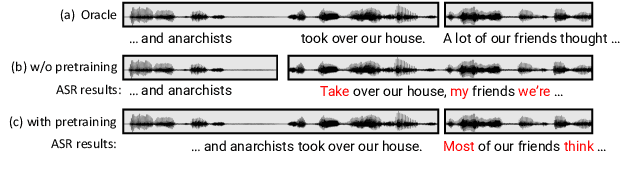
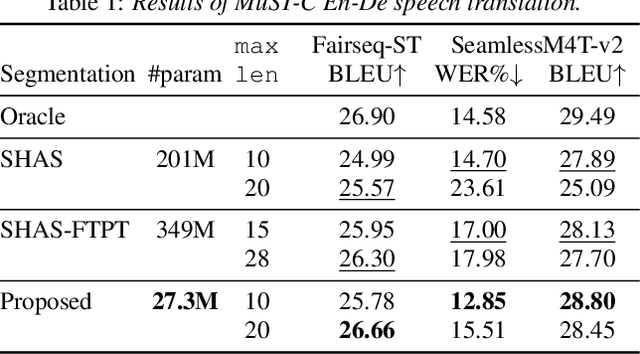

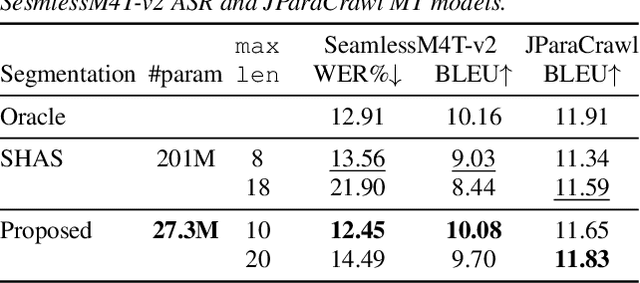
Speech segmentation is an essential part of speech translation (ST) systems in real-world scenarios. Since most ST models are designed to process speech segments, long-form audio must be partitioned into shorter segments before translation. Recently, data-driven approaches for the speech segmentation task have been developed. Although the approaches improve overall translation quality, a performance gap exists due to a mismatch between the models and ST systems. In addition, the prior works require large self-supervised speech models, which consume significant computational resources. In this work, we propose a segmentation model that achieves better speech translation quality with a small model size. We propose an ASR-with-punctuation task as an effective pre-training strategy for the segmentation model. We also show that proper integration of the speech segmentation model into the underlying ST system is critical to improve overall translation quality at inference time.