 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Segmentation Ambiguity in Neural Linguistic Steganography
Nov 12, 2022



Previous studies on neural linguistic steganography, except Ueoka et al. (2021), overlook the fact that the sender must detokenize cover texts to avoid arousing the eavesdropper's suspicion. In this paper, we demonstrate that segmentation ambiguity indeed causes occasional decoding failures at the receiver's side. With the near-ubiquity of subwords, this problem now affects any language. We propose simple tricks to overcome this problem, which are even applicable to languages without explicit word boundaries.
End-to-end Speech-to-Punctuated-Text Recognition
Jul 07, 2022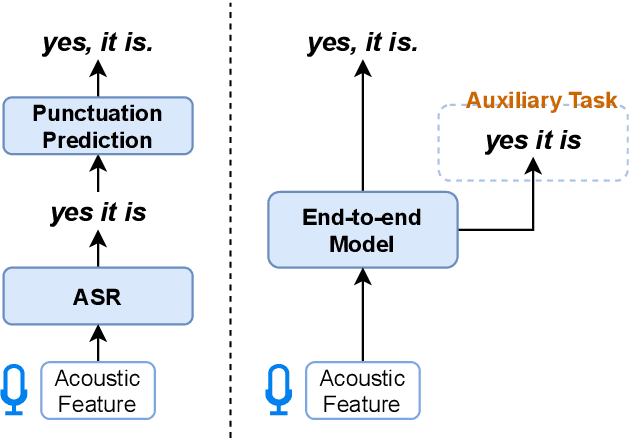
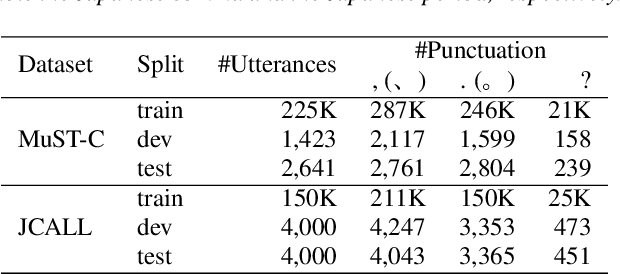

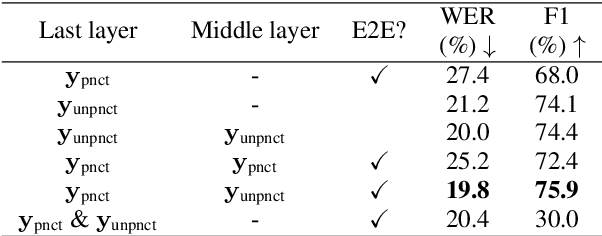
Conventional automatic speech recognition systems do not produce punctuation marks which are important for the readability of the speech recognition results. They are also needed for subsequent natural language processing tasks such as machine translation. There have been a lot of works on punctuation prediction models that insert punctuation marks into speech recognition results as post-processing. However, these studies do not utilize acoustic information for punctuation prediction and are directly affected by speech recognition errors. In this study, we propose an end-to-end model that takes speech as input and outputs punctuated texts. This model is expected to predict punctuation robustly against speech recognition errors while using acoustic information. We also propose to incorporate an auxiliary loss to train the model using the output of the intermediate layer and unpunctuated texts. Through experiments, we compare the performance of the proposed model to that of a cascaded system. The proposed model achieves higher punctuation prediction accuracy than the cascaded system without sacrificing the speech recognition error rate. It is also demonstrated that the multi-task learning using the intermediate output against the unpunctuated text is effective. Moreover, the proposed model has only about 1/7th of the parameters compared to the cascaded system.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021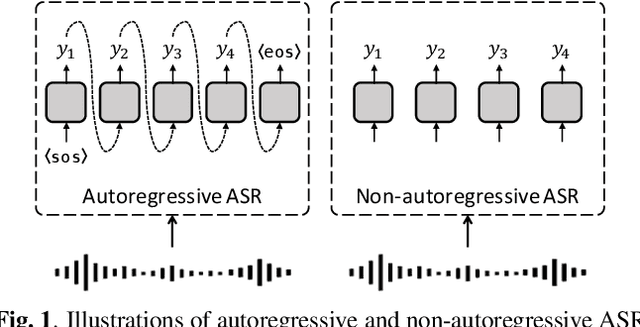

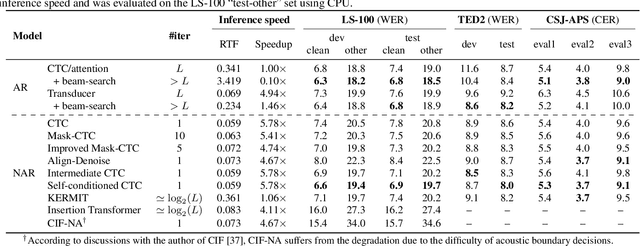
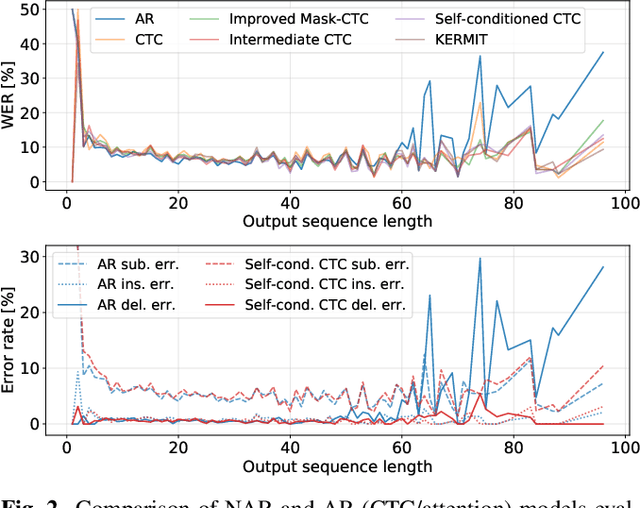
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Relaxing the Conditional Independence Assumption of CTC-based ASR by Conditioning on Intermediate Predictions
Apr 06, 2021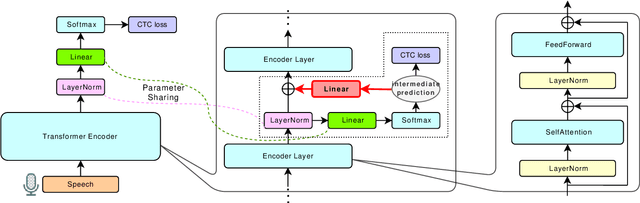
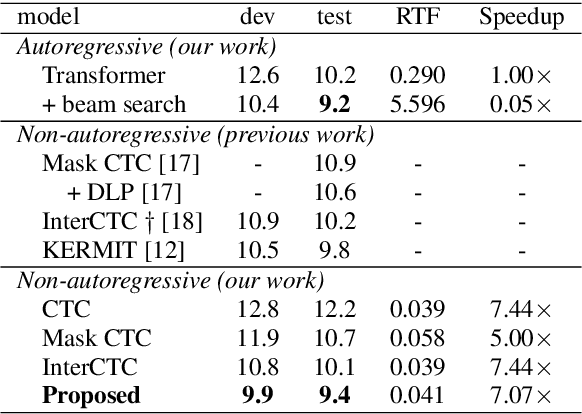
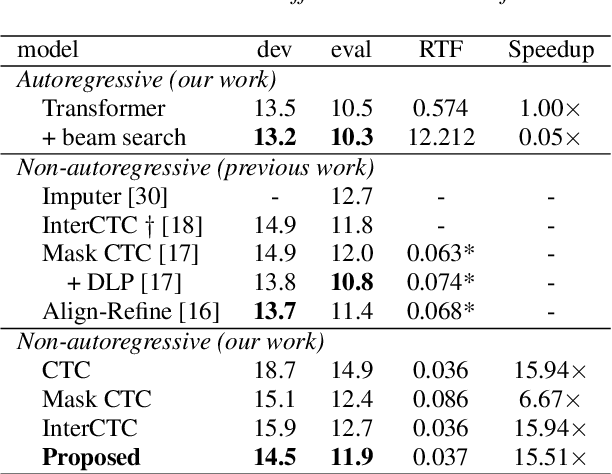

This paper proposes a method to relax the conditional independence assumption of connectionist temporal classification (CTC)-based automatic speech recognition (ASR) models. We train a CTC-based ASR model with auxiliary CTC losses in intermediate layers in addition to the original CTC loss in the last layer. During both training and inference, each generated prediction in the intermediate layers is summed to the input of the next layer to condition the prediction of the last layer on those intermediate predictions. Our method is easy to implement and retains the merits of CTC-based ASR: a simple model architecture and fast decoding speed. We conduct experiments on three different ASR corpora. Our proposed method improves a standard CTC model significantly (e.g., more than 20 % relative word error rate reduction on the WSJ corpus) with a little computational overhead. Moreover, for the TEDLIUM2 corpus and the AISHELL-1 corpus, it achieves a comparable performance to a strong autoregressive model with beam search, but the decoding speed is at least 30 times faster.