 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxing the Conditional Independence Assumption of CTC-based ASR by Conditioning on Intermediate Predictions
Paper and Code
Apr 06, 2021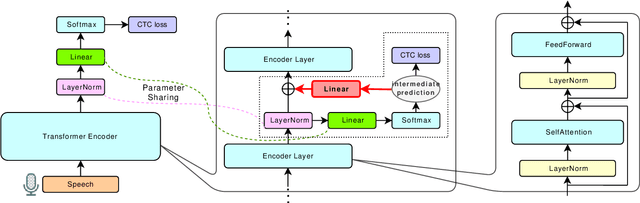
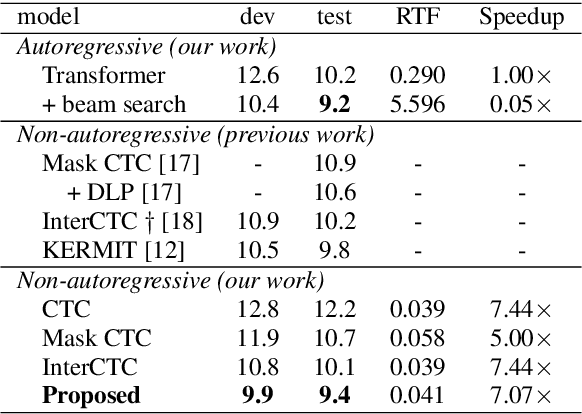
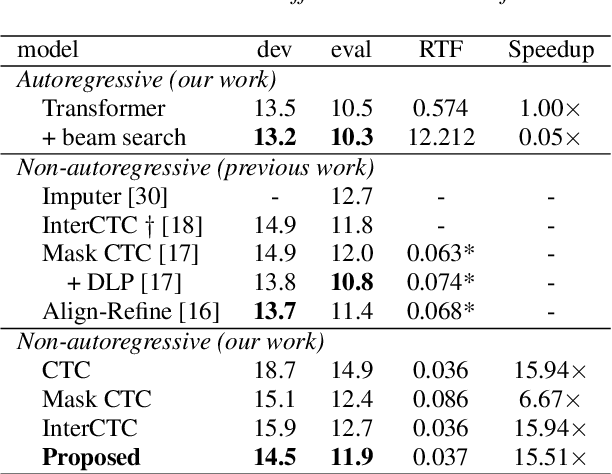

This paper proposes a method to relax the conditional independence assumption of connectionist temporal classification (CTC)-based automatic speech recognition (ASR) models. We train a CTC-based ASR model with auxiliary CTC losses in intermediate layers in addition to the original CTC loss in the last layer. During both training and inference, each generated prediction in the intermediate layers is summed to the input of the next layer to condition the prediction of the last layer on those intermediate predictions. Our method is easy to implement and retains the merits of CTC-based ASR: a simple model architecture and fast decoding speed. We conduct experiments on three different ASR corpora. Our proposed method improves a standard CTC model significantly (e.g., more than 20 % relative word error rate reduction on the WSJ corpus) with a little computational overhead. Moreover, for the TEDLIUM2 corpus and the AISHELL-1 corpus, it achieves a comparable performance to a strong autoregressive model with beam search, but the decoding speed is at least 30 times faster.