 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Training of RNN-Transducer with Sampled Softmax
Paper and Code
Mar 31, 2022
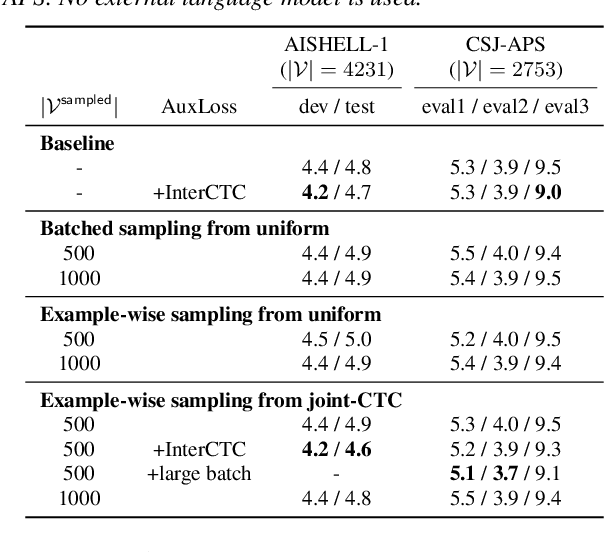
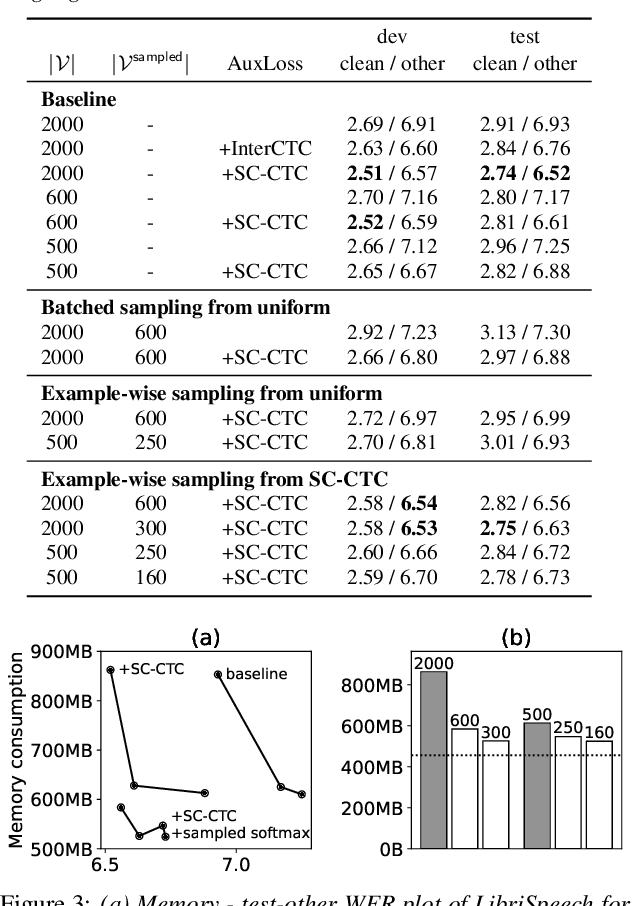
RNN-Transducer has been one of promising architectures for end-to-end automatic speech recognition. Although RNN-Transducer has many advantages including its strong accuracy and streaming-friendly property, its high memory consumption during training has been a critical problem for development. In this work, we propose to apply sampled softmax to RNN-Transducer, which requires only a small subset of vocabulary during training thus saves its memory consumption. We further extend sampled softmax to optimize memory consumption for a minibatch, and employ distributions of auxiliary CTC losses for sampling vocabulary to improve model accuracy. We present experimental results on LibriSpeech, AISHELL-1, and CSJ-APS, where sampled softmax greatly reduces memory consumption and still maintains the accuracy of the baseline model.