 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Training for End-to-End Streaming Automatic Speech Recognition Model with Punctuation
Jun 02, 2023Punctuated text prediction is crucial for automatic speech recognition as it enhances readability and impacts downstream natural language processing tasks. In streaming scenarios, the ability to predict punctuation in real-time is particularly desirable but presents a difficult technical challenge. In this work, we propose a method for predicting punctuated text from input speech using a chunk-based Transformer encoder trained with Connectionist Temporal Classification (CTC) loss. The acoustic model trained with long sequences by concatenating the input and target sequences can learn punctuation marks attached to the end of sentences more effectively. Additionally, by combining CTC losses on the chunks and utterances, we achieved both the improved F1 score of punctuation prediction and Word Error Rate (WER).
Better Intermediates Improve CTC Inference
Apr 01, 2022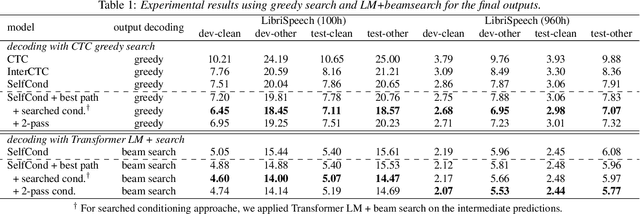

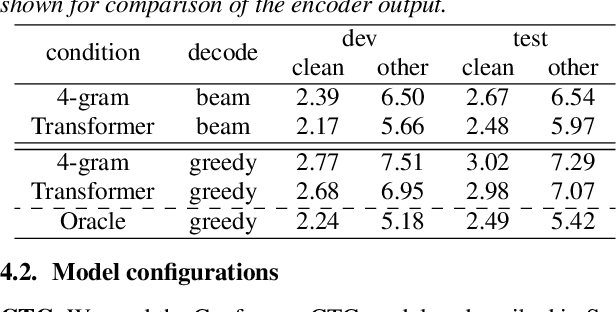
This paper proposes a method for improved CTC inference with searched intermediates and multi-pass conditioning. The paper first formulates self-conditioned CTC as a probabilistic model with an intermediate prediction as a latent representation and provides a tractable conditioning framework. We then propose two new conditioning methods based on the new formulation: (1) Searched intermediate conditioning that refines intermediate predictions with beam-search, (2) Multi-pass conditioning that uses predictions of previous inference for conditioning the next inference. These new approaches enable better conditioning than the original self-conditioned CTC during inference and improve the final performance. Experiments with the LibriSpeech dataset show relative 3%/12% performance improvement at the maximum in test clean/other sets compared to the original self-conditioned CTC.
Memory-Efficient Training of RNN-Transducer with Sampled Softmax
Mar 31, 2022
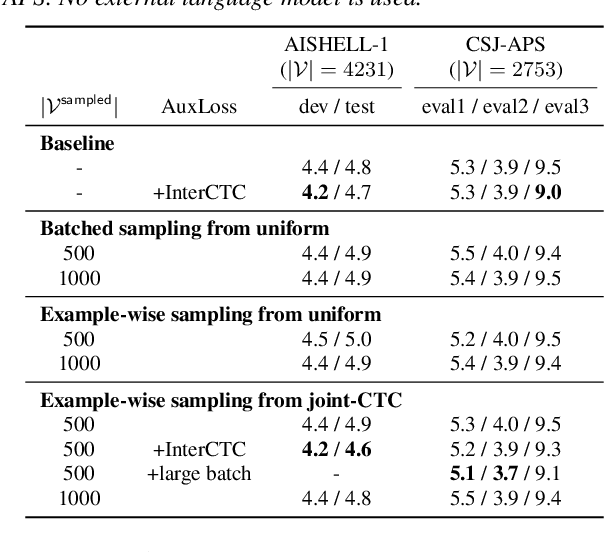
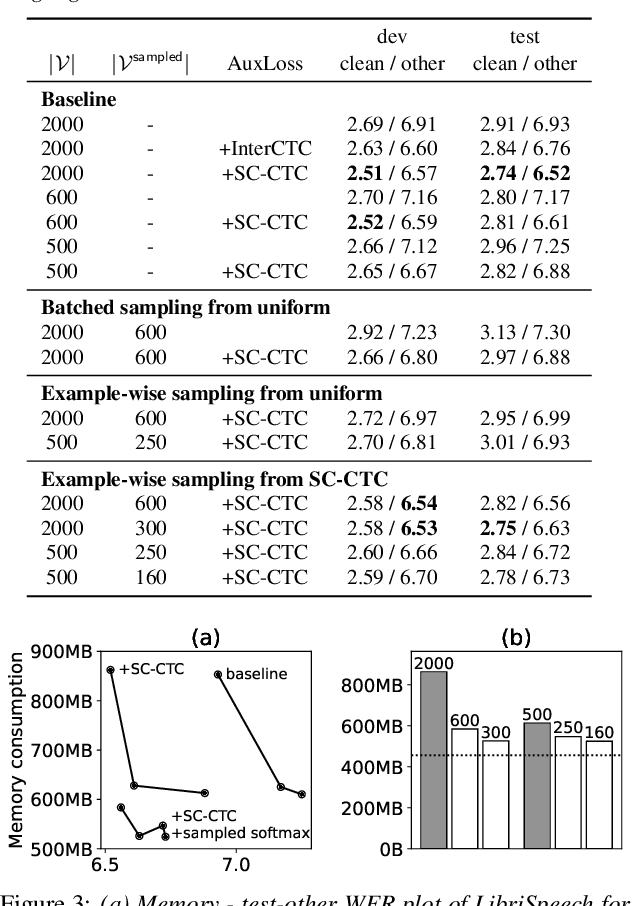
RNN-Transducer has been one of promising architectures for end-to-end automatic speech recognition. Although RNN-Transducer has many advantages including its strong accuracy and streaming-friendly property, its high memory consumption during training has been a critical problem for development. In this work, we propose to apply sampled softmax to RNN-Transducer, which requires only a small subset of vocabulary during training thus saves its memory consumption. We further extend sampled softmax to optimize memory consumption for a minibatch, and employ distributions of auxiliary CTC losses for sampling vocabulary to improve model accuracy. We present experimental results on LibriSpeech, AISHELL-1, and CSJ-APS, where sampled softmax greatly reduces memory consumption and still maintains the accuracy of the baseline model.