 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigidity-Aware 3D Gaussian Deformation from a Single Image
Sep 26, 2025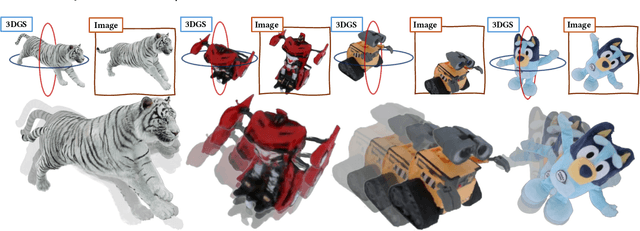
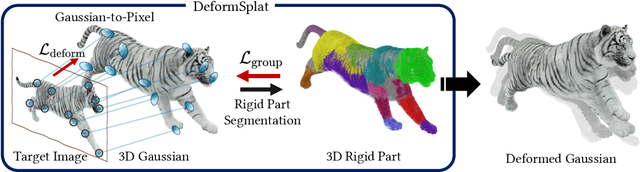

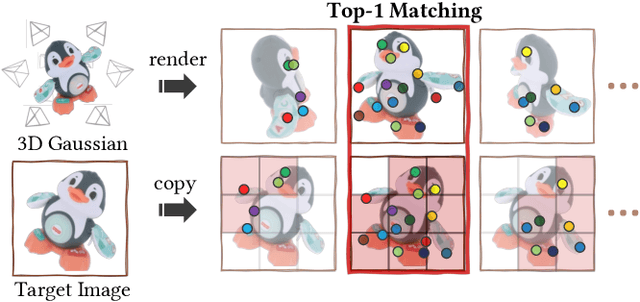
Reconstructing object deformation from a single image remains a significant challenge in computer vision and graphics. Existing methods typically rely on multi-view video to recover deformation, limiting their applicability under constrained scenarios. To address this, we propose DeformSplat, a novel framework that effectively guides 3D Gaussian deformation from only a single image. Our method introduces two main technical contributions. First, we present Gaussian-to-Pixel Matching which bridges the domain gap between 3D Gaussian representations and 2D pixel observations. This enables robust deformation guidance from sparse visual cues. Second, we propose Rigid Part Segmentation consisting of initialization and refinement. This segmentation explicitly identifies rigid regions, crucial for maintaining geometric coherence during deformation. By combining these two techniques, our approach can reconstruct consistent deformations from a single image. Extensive experiments demonstrate that our approach significantly outperforms existing methods and naturally extends to various applications,such as frame interpolation and interactive object manipulation.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Improved Training for End-to-End Streaming Automatic Speech Recognition Model with Punctuation
Jun 02, 2023



Punctuated text prediction is crucial for automatic speech recognition as it enhances readability and impacts downstream natural language processing tasks. In streaming scenarios, the ability to predict punctuation in real-time is particularly desirable but presents a difficult technical challenge. In this work, we propose a method for predicting punctuated text from input speech using a chunk-based Transformer encoder trained with Connectionist Temporal Classification (CTC) loss. The acoustic model trained with long sequences by concatenating the input and target sequences can learn punctuation marks attached to the end of sentences more effectively. Additionally, by combining CTC losses on the chunks and utterances, we achieved both the improved F1 score of punctuation prediction and Word Error Rate (WER).
Efficient Storage of Fine-Tuned Models via Low-Rank Approximation of Weight Residuals
May 28, 2023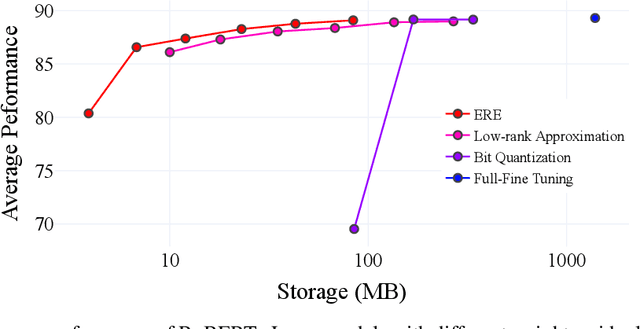
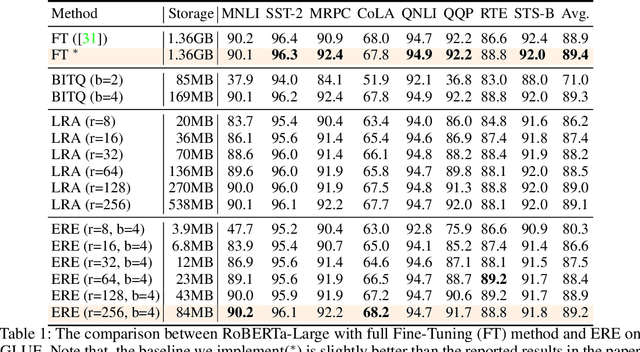
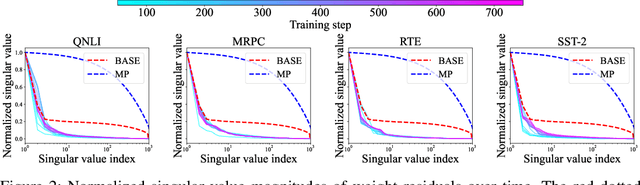

In this paper, we present an efficient method for storing fine-tuned models by leveraging the low-rank properties of weight residuals. Our key observation is that weight residuals in large overparameterized models exhibit even stronger low-rank characteristics. Based on this insight, we propose Efficient Residual Encoding (ERE), a novel approach that achieves efficient storage of fine-tuned model weights by approximating the low-rank weight residuals. Furthermore, we analyze the robustness of weight residuals and push the limit of storage efficiency by utilizing additional quantization and layer-wise rank allocation. Our experimental results demonstrate that our method significantly reduces memory footprint while preserving performance in various tasks and modalities. We release our code.
Blank Collapse: Compressing CTC emission for the faster decoding
Oct 31, 2022
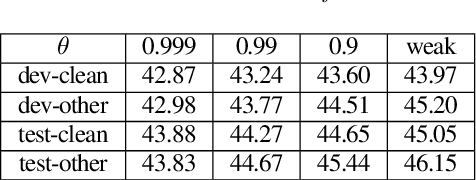

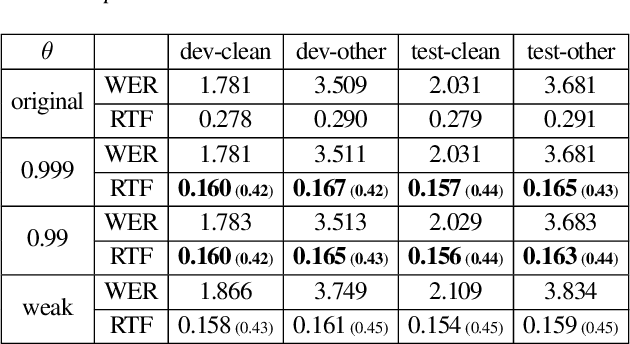
Connectionist Temporal Classification (CTC) model is a very efficient method for modeling sequences, especially for speech data. In order to use CTC model as an Automatic Speech Recognition (ASR) task, the beam search decoding with an external language model like n-gram LM is necessary to obtain reasonable results. In this paper we analyze the blank label in CTC beam search deeply and propose a very simple method to reduce the amount of calculation resulting in faster beam search decoding speed. With this method, we can get up to 78% faster decoding speed than ordinary beam search decoding with a very small loss of accuracy in LibriSpeech datasets. We prove this method is effective not only practically by experiments but also theoretically by mathematical reasoning. We also observe that this reduction is more obvious if the accuracy of the model is higher.
Integration of Pre-trained Networks with Continuous Token Interface for End-to-End Spoken Language Understanding
Apr 15, 2021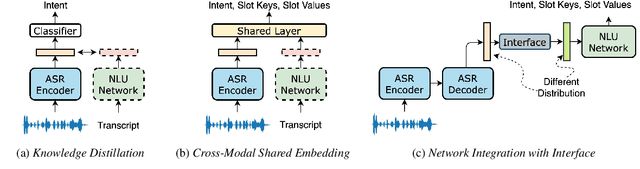
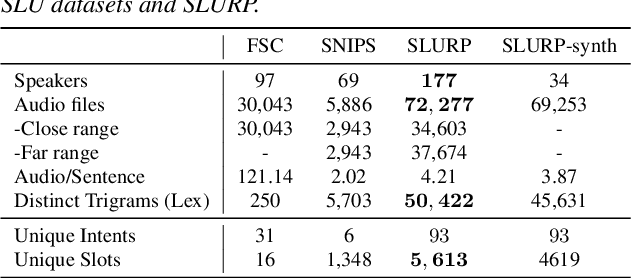
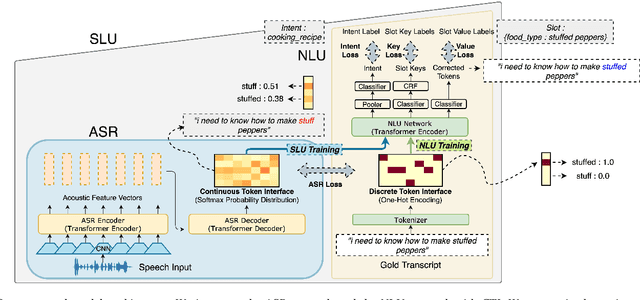

Most End-to-End (E2E) SLU networks leverage the pre-trained ASR networks but still lack the capability to understand the semantics of utterances, crucial for the SLU task. To solve this, recently proposed studies use pre-trained NLU networks. However, it is not trivial to fully utilize both pre-trained networks; many solutions were proposed, such as Knowledge Distillation, cross-modal shared embedding, and network integration with Interface. We propose a simple and robust integration method for the E2E SLU network with novel Interface, Continuous Token Interface (CTI), the junctional representation of the ASR and NLU networks when both networks are pre-trained with the same vocabulary. Because the only difference is the noise level, we directly feed the ASR network's output to the NLU network. Thus, we can train our SLU network in an E2E manner without additional modules, such as Gumbel-Softmax. We evaluate our model using SLURP, a challenging SLU dataset and achieve state-of-the-art scores on both intent classification and slot filling tasks. We also verify the NLU network, pre-trained with Masked Language Model, can utilize a noisy textual representation of CTI. Moreover, we show our model can be trained with multi-task learning from heterogeneous data even after integration with CTI.