 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Storage of Fine-Tuned Models via Low-Rank Approximation of Weight Residuals
Paper and Code
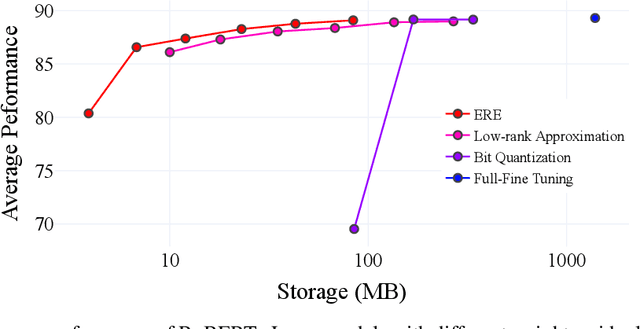
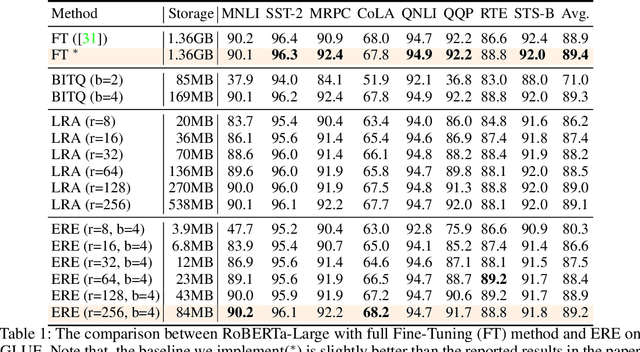
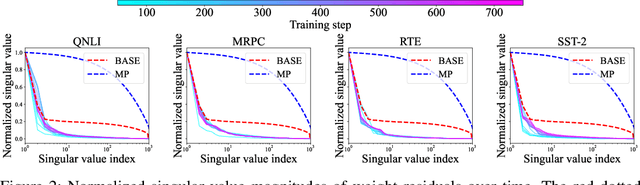

In this paper, we present an efficient method for storing fine-tuned models by leveraging the low-rank properties of weight residuals. Our key observation is that weight residuals in large overparameterized models exhibit even stronger low-rank characteristics. Based on this insight, we propose Efficient Residual Encoding (ERE), a novel approach that achieves efficient storage of fine-tuned model weights by approximating the low-rank weight residuals. Furthermore, we analyze the robustness of weight residuals and push the limit of storage efficiency by utilizing additional quantization and layer-wise rank allocation. Our experimental results demonstrate that our method significantly reduces memory footprint while preserving performance in various tasks and modalities. We release our code.