 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Pre-trained Networks with Continuous Token Interface for End-to-End Spoken Language Understanding
Apr 15, 2021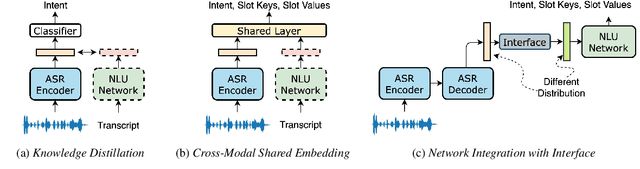
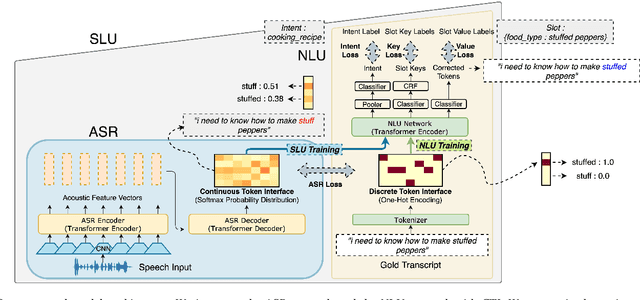

Most End-to-End (E2E) SLU networks leverage the pre-trained ASR networks but still lack the capability to understand the semantics of utterances, crucial for the SLU task. To solve this, recently proposed studies use pre-trained NLU networks. However, it is not trivial to fully utilize both pre-trained networks; many solutions were proposed, such as Knowledge Distillation, cross-modal shared embedding, and network integration with Interface. We propose a simple and robust integration method for the E2E SLU network with novel Interface, Continuous Token Interface (CTI), the junctional representation of the ASR and NLU networks when both networks are pre-trained with the same vocabulary. Because the only difference is the noise level, we directly feed the ASR network's output to the NLU network. Thus, we can train our SLU network in an E2E manner without additional modules, such as Gumbel-Softmax. We evaluate our model using SLURP, a challenging SLU dataset and achieve state-of-the-art scores on both intent classification and slot filling tasks. We also verify the NLU network, pre-trained with Masked Language Model, can utilize a noisy textual representation of CTI. Moreover, we show our model can be trained with multi-task learning from heterogeneous data even after integration with CTI.
Pansori: ASR Corpus Generation from Open Online Video Contents
Dec 23, 2018
This paper introduces Pansori, a program used to create ASR (automatic speech recognition) corpora from online video contents. It utilizes a cloud-based speech API to easily create a corpus in different languages. Using this program, we semi-automatically generated the Pansori-TEDxKR dataset from Korean TED conference talks with community-transcribed subtitles. It is the first high-quality corpus for the Korean language freely available for independent research. Pansori is released as an open-source software and the generated corpus is released under a permissive public license for community use and participation.
* 5 pages with appendix
Single Channel Speech Enhancement Using Outlier Detection
May 04, 2016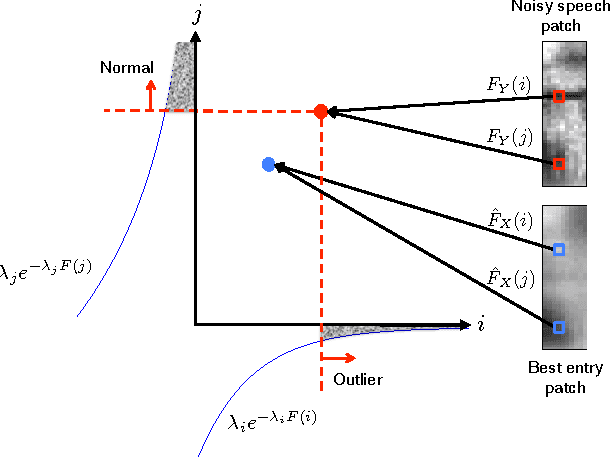
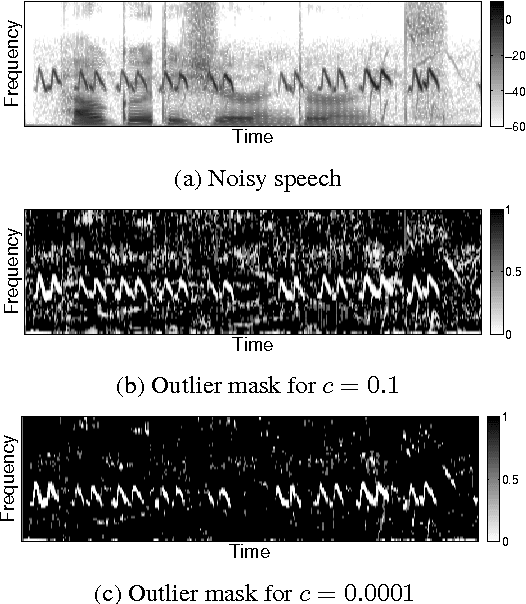
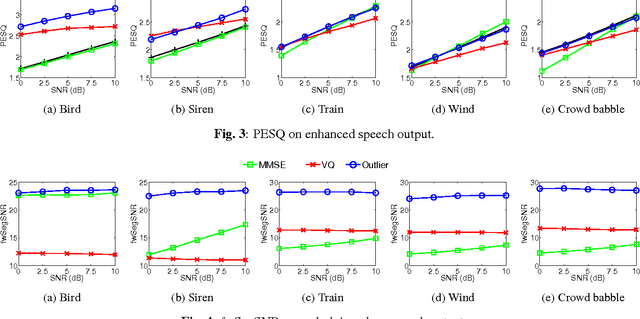
Distortion of the underlying speech is a common problem for single-channel speech enhancement algorithms, and hinders such methods from being used more extensively. A dictionary based speech enhancement method that emphasizes preserving the underlying speech is proposed. Spectral patches of clean speech are sampled and clustered to train a dictionary. Given a noisy speech spectral patch, the best matching dictionary entry is selected and used to estimate the noise power at each time-frequency bin. The noise estimation step is formulated as an outlier detection problem, where the noise at each bin is assumed present only if it is an outlier to the corresponding bin of the best matching dictionary entry. This framework assigns higher priority in removing spectral elements that strongly deviate from a typical spoken unit stored in the trained dictionary. Even without the aid of a separate noise model, this method can achieve significant noise reduction for various non-stationary noises, while effectively preserving the underlying speech in more challenging noisy environments.