 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Oct 23, 2020



Several recent work on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this work, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel-spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real-time on CPU with comparable quality to an autoregressive counterpart.
Revisiting Modularized Multilingual NMT to Meet Industrial Demands
Oct 19, 2020
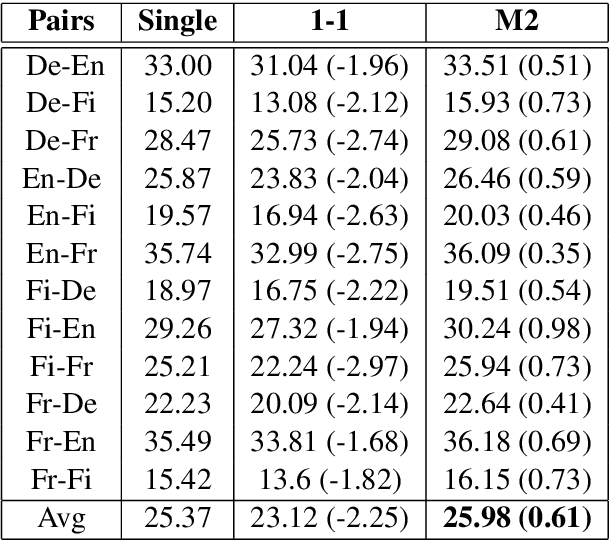
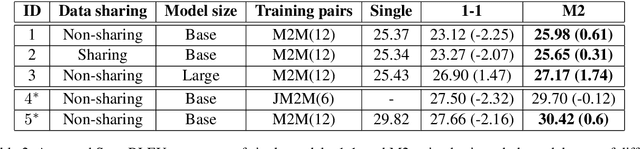
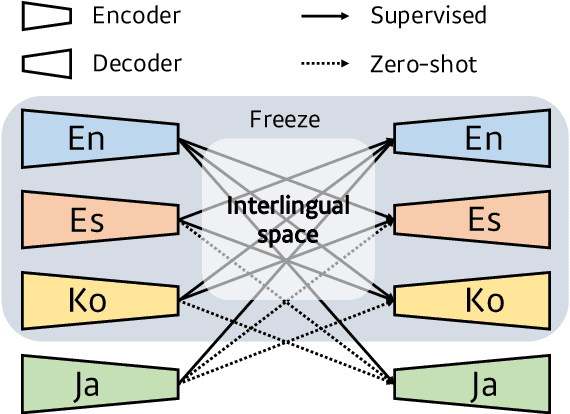
The complete sharing of parameters for multilingual translation (1-1) has been the mainstream approach in current research. However, degraded performance due to the capacity bottleneck and low maintainability hinders its extensive adoption in industries. In this study, we revisit the multilingual neural machine translation model that only share modules among the same languages (M2) as a practical alternative to 1-1 to satisfy industrial requirements. Through comprehensive experiments, we identify the benefits of multi-way training and demonstrate that the M2 can enjoy these benefits without suffering from the capacity bottleneck. Furthermore, the interlingual space of the M2 allows convenient modification of the model. By leveraging trained modules, we find that incrementally added modules exhibit better performance than singly trained models. The zero-shot performance of the added modules is even comparable to supervised models. Our findings suggest that the M2 can be a competent candidate for multilingual translation in industries.