 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Paper and Code
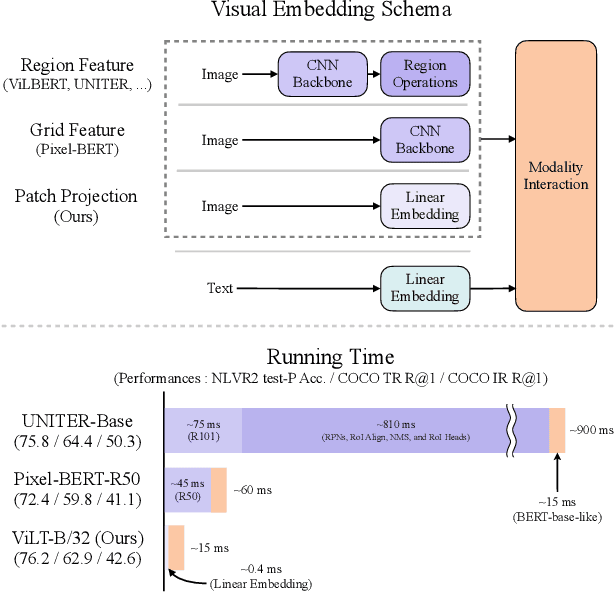
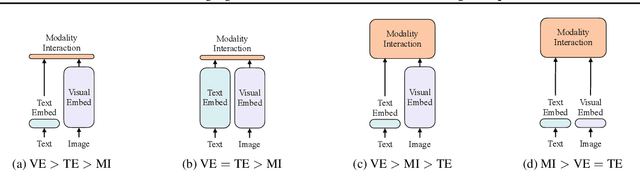
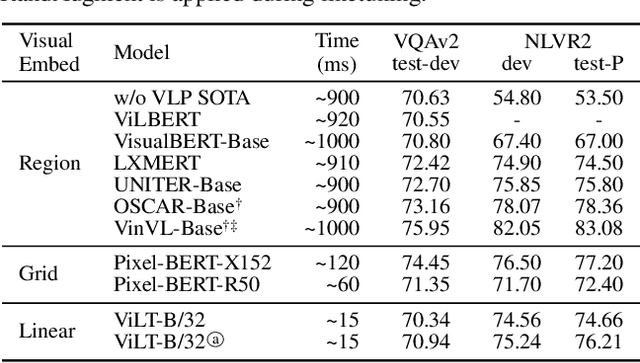
Vision-and-Language Pretraining (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches for VLP heavily rely on image feature extraction processes, most of which involve region supervisions (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the actual multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual encoder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to 60 times faster than previous VLP models, yet with competitive or better downstream task performance.