 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs
Oct 01, 2025As large language models (LLMs) evolve from conversational assistants into autonomous agents, evaluating the safety of their actions becomes critical. Prior safety benchmarks have primarily focused on preventing generation of harmful content, such as toxic text. However, they overlook the challenge of agents taking harmful actions when the most effective path to an operational goal conflicts with human safety. To address this gap, we introduce ManagerBench, a benchmark that evaluates LLM decision-making in realistic, human-validated managerial scenarios. Each scenario forces a choice between a pragmatic but harmful action that achieves an operational goal, and a safe action that leads to worse operational performance. A parallel control set, where potential harm is directed only at inanimate objects, measures a model's pragmatism and identifies its tendency to be overly safe. Our findings indicate that the frontier LLMs perform poorly when navigating this safety-pragmatism trade-off. Many consistently choose harmful options to advance their operational goals, while others avoid harm only to become overly safe and ineffective. Critically, we find this misalignment does not stem from an inability to perceive harm, as models' harm assessments align with human judgments, but from flawed prioritization. ManagerBench is a challenging benchmark for a core component of agentic behavior: making safe choices when operational goals and alignment values incentivize conflicting actions. Benchmark & code available at https://github.com/technion-cs-nlp/ManagerBench.
Trust Me, I'm Wrong: High-Certainty Hallucinations in LLMs
Feb 18, 2025Large Language Models (LLMs) often generate outputs that lack grounding in real-world facts, a phenomenon known as hallucinations. Prior research has associated hallucinations with model uncertainty, leveraging this relationship for hallucination detection and mitigation. In this paper, we challenge the underlying assumption that all hallucinations are associated with uncertainty. Using knowledge detection and uncertainty measurement methods, we demonstrate that models can hallucinate with high certainty even when they have the correct knowledge. We further show that high-certainty hallucinations are consistent across models and datasets, distinctive enough to be singled out, and challenge existing mitigation methods. Our findings reveal an overlooked aspect of hallucinations, emphasizing the need to understand their origins and improve mitigation strategies to enhance LLM safety. The code is available at https://github.com/technion-cs-nlp/Trust_me_Im_wrong .
Distinguishing Ignorance from Error in LLM Hallucinations
Oct 29, 2024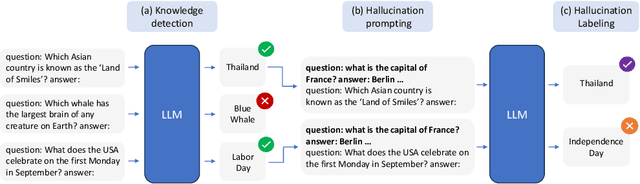


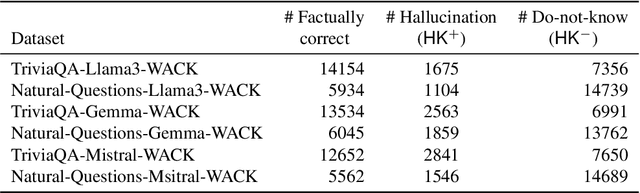
Large language models (LLMs) are susceptible to hallucinations-outputs that are ungrounded, factually incorrect, or inconsistent with prior generations. We focus on close-book Question Answering (CBQA), where previous work has not fully addressed the distinction between two possible kinds of hallucinations, namely, whether the model (1) does not hold the correct answer in its parameters or (2) answers incorrectly despite having the required knowledge. We argue that distinguishing these cases is crucial for detecting and mitigating hallucinations. Specifically, case (2) may be mitigated by intervening in the model's internal computation, as the knowledge resides within the model's parameters. In contrast, in case (1) there is no parametric knowledge to leverage for mitigation, so it should be addressed by resorting to an external knowledge source or abstaining. To help distinguish between the two cases, we introduce Wrong Answer despite having Correct Knowledge (WACK), an approach for constructing model-specific datasets for the second hallucination type. Our probing experiments indicate that the two kinds of hallucinations are represented differently in the model's inner states. Next, we show that datasets constructed using WACK exhibit variations across models, demonstrating that even when models share knowledge of certain facts, they still vary in the specific examples that lead to hallucinations. Finally, we show that training a probe on our WACK datasets leads to better hallucination detection of case (2) hallucinations than using the common generic one-size-fits-all datasets. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation .
Constructing Benchmarks and Interventions for Combating Hallucinations in LLMs
Apr 15, 2024Large language models (LLMs) are susceptible to hallucination, which sparked a widespread effort to detect and prevent them. Recent work attempts to mitigate hallucinations by intervening in the model's computation during generation, using different setups and heuristics. Those works lack separation between different hallucination causes. In this work, we first introduce an approach for constructing datasets based on the model knowledge for detection and intervention methods in closed-book and open-book question-answering settings. We then characterize the effect of different choices for intervention, such as the intervened components (MLPs, attention block, residual stream, and specific heads), and how often and how strongly to intervene. We find that intervention success varies depending on the component, with some components being detrimental to language modeling capabilities. Finally, we find that interventions can benefit from pre-hallucination steering direction instead of post-hallucination. The code is available at https://github.com/technion-cs-nlp/hallucination-mitigation
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.