 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deep Reinforcement Learning Approach for Multi-Objective Scheduling With Varying Queue Sizes
Jul 17, 2020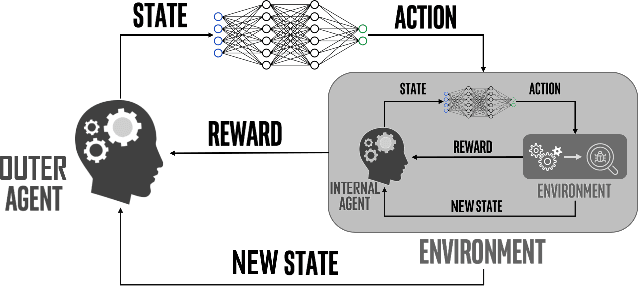

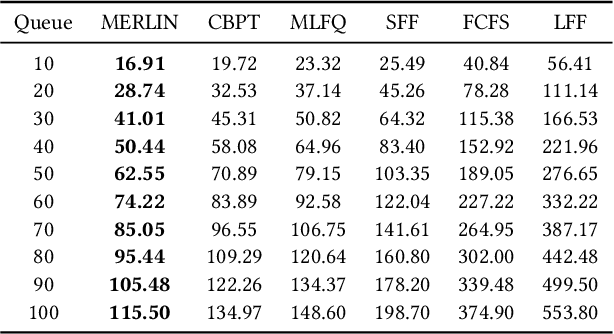
Multi-objective task scheduling (MOTS) is the task scheduling while optimizing multiple and possibly contradicting constraints. A challenging extension of this problem occurs when every individual task is a multi-objective optimization problem by itself. While deep reinforcement learning (DRL) has been successfully applied to complex sequential problems, its application to the MOTS domain has been stymied by two challenges. The first challenge is the inability of the DRL algorithm to ensure that every item is processed identically regardless of its position in the queue. The second challenge is the need to manage large queues, which results in large neural architectures and long training times. In this study we present MERLIN, a robust, modular and near-optimal DRL-based approach for multi-objective task scheduling. MERLIN applies a hierarchical approach to the MOTS problem by creating one neural network for the processing of individual tasks and another for the scheduling of the overall queue. In addition to being smaller and with shorted training times, the resulting architecture ensures that an item is processed in the same manner regardless of its position in the queue. Additionally, we present a novel approach for efficiently applying DRL-based solutions on very large queues, and demonstrate how we effectively scale MERLIN to process queue sizes that are larger by orders of magnitude than those on which it was trained. Extensive evaluation on multiple queue sizes show that MERLIN outperforms multiple well-known baselines by a large margin (>22%).
ASPIRE: Automated Security Policy Implementation Using Reinforcement Learning
May 25, 2019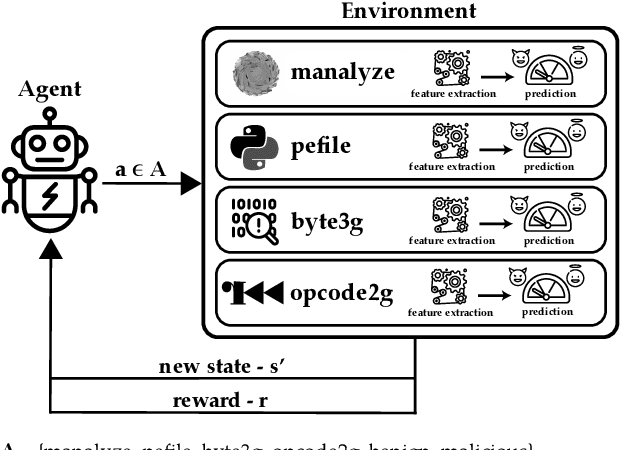

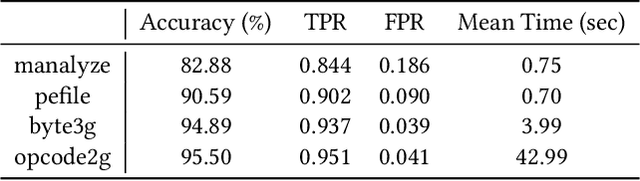
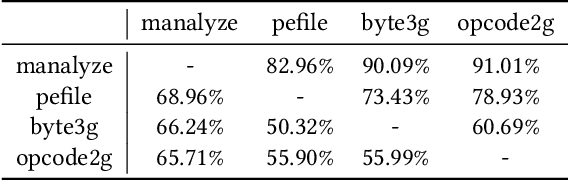
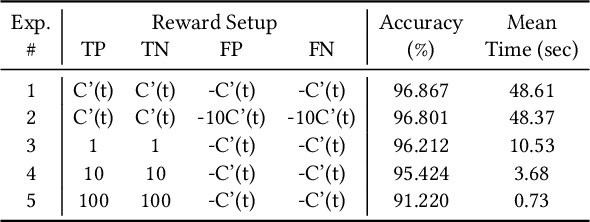
Malware detection is an ever-present challenge for all organizational gatekeepers. Organizations often deploy numerous different malware detection tools, and then combine their output to produce a final classification for an inspected file. This approach has two significant drawbacks. First, it requires large amounts of computing resources and time since every incoming file needs to be analyzed by all detectors. Secondly, it is difficult to accurately and dynamically enforce a predefined security policy that comports with the needs of each organization (e.g., how tolerant is the organization to false negatives and false positives). In this study we propose ASPIRE, a reinforcement learning (RL)-based method for malware detection. Our approach receives the organizational policy -- defined solely by the perceived costs of correct/incorrect classifications and of computing resources -- and then dynamically assigns detection tools and sets the detection threshold for each inspected file. We demonstrate the effectiveness and robustness of our approach by conducting an extensive evaluation on multiple organizational policies. ASPIRE performed well in all scenarios, even achieving near-optimal accuracy of 96.21% (compared to an optimum of 96.86%) at approximately 20% of the running time of this baseline.