 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReHub: Linear Complexity Graph Transformers with Adaptive Hub-Spoke Reassignment
Paper and Code
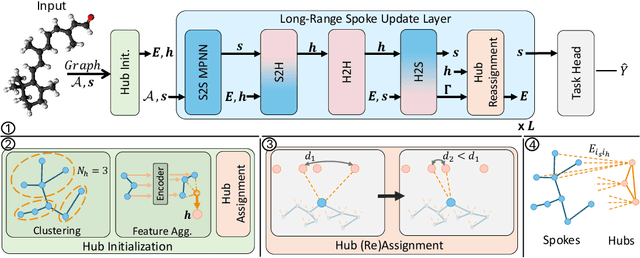
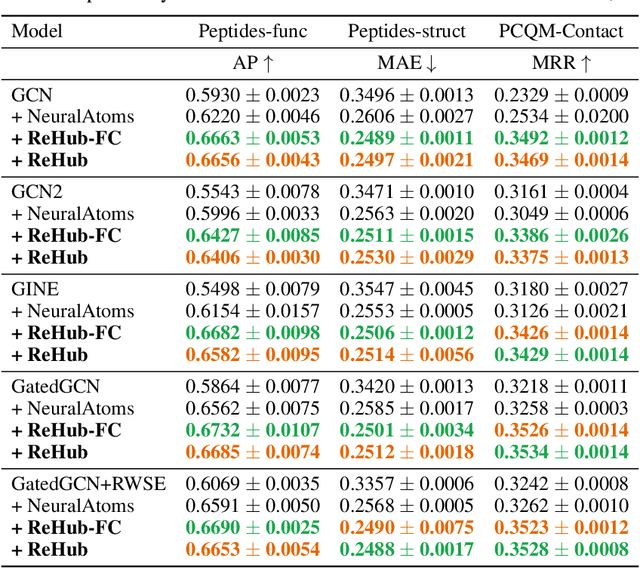
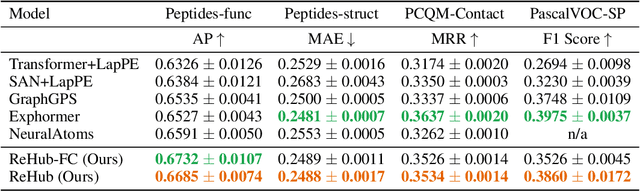
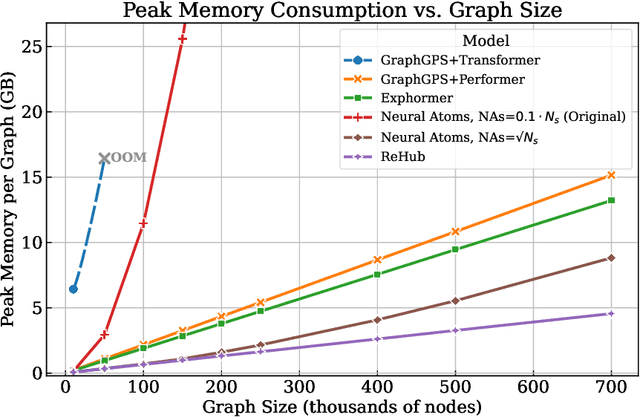
We present ReHub, a novel graph transformer architecture that achieves linear complexity through an efficient reassignment technique between nodes and virtual nodes. Graph transformers have become increasingly important in graph learning for their ability to utilize long-range node communication explicitly, addressing limitations such as oversmoothing and oversquashing found in message-passing graph networks. However, their dense attention mechanism scales quadratically with the number of nodes, limiting their applicability to large-scale graphs. ReHub draws inspiration from the airline industry's hub-and-spoke model, where flights are assigned to optimize operational efficiency. In our approach, graph nodes (spokes) are dynamically reassigned to a fixed number of virtual nodes (hubs) at each model layer. Recent work, Neural Atoms (Li et al., 2024), has demonstrated impressive and consistent improvements over GNN baselines by utilizing such virtual nodes; their findings suggest that the number of hubs strongly influences performance. However, increasing the number of hubs typically raises complexity, requiring a trade-off to maintain linear complexity. Our key insight is that each node only needs to interact with a small subset of hubs to achieve linear complexity, even when the total number of hubs is large. To leverage all hubs without incurring additional computational costs, we propose a simple yet effective adaptive reassignment technique based on hub-hub similarity scores, eliminating the need for expensive node-hub computations. Our experiments on LRGB indicate a consistent improvement in results over the base method, Neural Atoms, while maintaining a linear complexity. Remarkably, our sparse model achieves performance on par with its non-sparse counterpart. Furthermore, ReHub outperforms competitive baselines and consistently ranks among top performers across various benchmarks.