 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic Regret Analysis and Adaptive Regularization Algorithm for On-Policy Robot Imitation Learning
Paper and Code

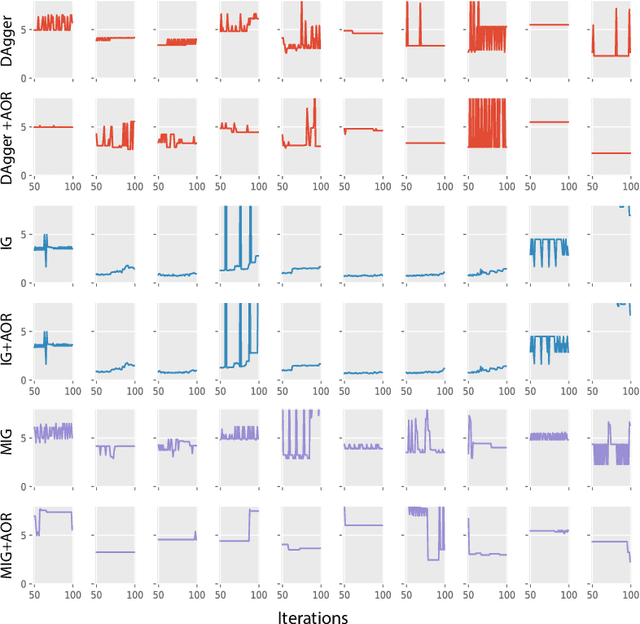
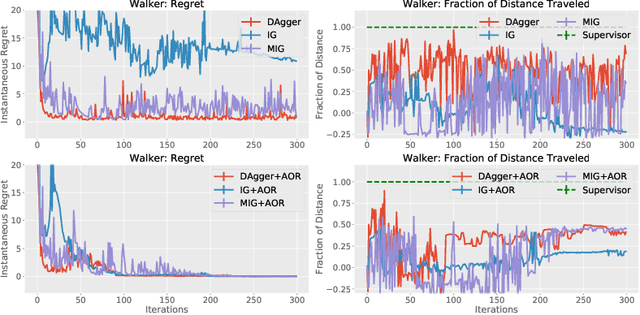
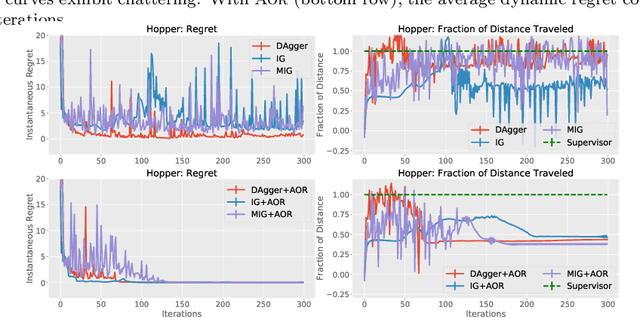
On-policy imitation learning algorithms such as Dagger evolve a robot control policy by executing it, measuring performance (loss), obtaining corrective feedback from a supervisor, and generating the next policy. As the loss between iterations can vary unpredictably, a fundamental question is under what conditions this process will eventually achieve a converged policy. If one assumes the underlying trajectory distribution is static (stationary), it is possible to prove convergence for Dagger. Cheng and Boots (2018) consider the more realistic model for robotics where the underlying trajectory distribution, which is a function of the policy, is dynamic and show that it is possible to prove convergence when a condition on the rate of change of the trajectory distributions is satisfied. In this paper, we reframe that result using dynamic regret theory from the field of Online Optimization to prove convergence to locally optimal policies for Dagger, Imitation Gradient, and Multiple Imitation Gradient. These results inspire a new algorithm, Adaptive On-Policy Regularization (AOR), that ensures the conditions for convergence. We present simulation results with cart-pole balancing and walker locomotion benchmarks that suggest AOR can significantly decrease dynamic regret and chattering. To our knowledge, this the first application of dynamic regret theory to imitation learning.