 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMGSD: Multi-Modal Gaussian Shape Descriptors for Correspondence Matching in 1D and 2D Deformable Objects
Paper and Code
Oct 09, 2020

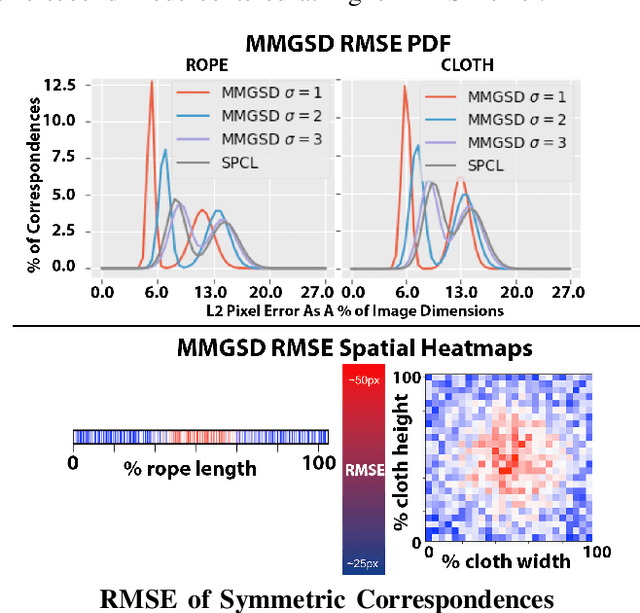
We explore learning pixelwise correspondences between images of deformable objects in different configurations. Traditional correspondence matching approaches such as SIFT, SURF, and ORB can fail to provide sufficient contextual information for fine-grained manipulation. We propose Multi-Modal Gaussian Shape Descriptor (MMGSD), a new visual representation of deformable objects which extends ideas from dense object descriptors to predict all symmetric correspondences between different object configurations. MMGSD is learned in a self-supervised manner from synthetic data and produces correspondence heatmaps with measurable uncertainty. In simulation, experiments suggest that MMGSD can achieve an RMSE of 32.4 and 31.3 for square cloth and braided synthetic nylon rope respectively. The results demonstrate an average of 47.7% improvement over a provided baseline based on contrastive learning, symmetric pixel-wise contrastive loss (SPCL), as opposed to MMGSD which enforces distributional continuity.