 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Paper and Code
Mar 03, 2022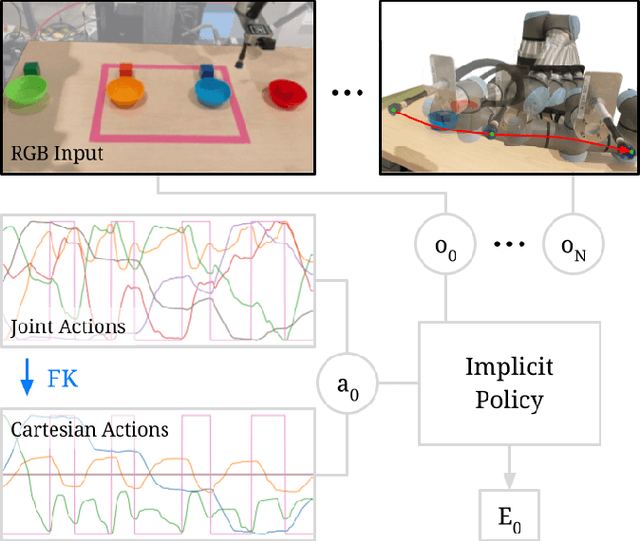
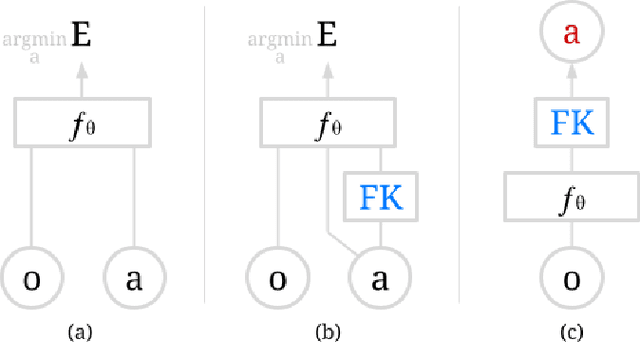
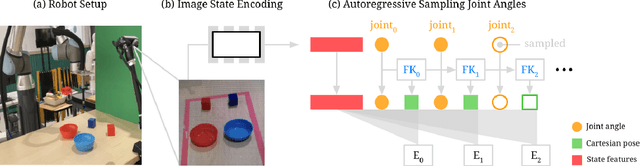
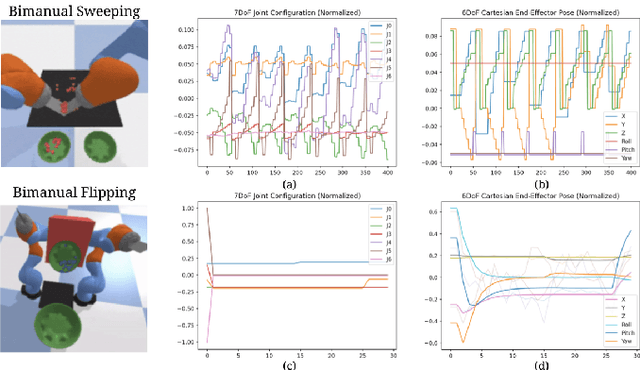
Action representation is an important yet often overlooked aspect in end-to-end robot learning with deep networks. Choosing one action space over another (e.g. target joint positions, or Cartesian end-effector poses) can result in surprisingly stark performance differences between various downstream tasks -- and as a result, considerable research has been devoted to finding the right action space for a given application. However, in this work, we instead investigate how our models can discover and learn for themselves which action space to use. Leveraging recent work on implicit behavioral cloning, which takes both observations and actions as input, we demonstrate that it is possible to present the same action in multiple different spaces to the same policy -- allowing it to learn inductive patterns from each space. Specifically, we study the benefits of combining Cartesian and joint action spaces in the context of learning manipulation skills. To this end, we present Implicit Kinematic Policies (IKP), which incorporates the kinematic chain as a differentiable module within the deep network. Quantitative experiments across several simulated continuous control tasks -- from scooping piles of small objects, to lifting boxes with elbows, to precise block insertion with miscalibrated robots -- suggest IKP not only learns complex prehensile and non-prehensile manipulation from pixels better than baseline alternatives, but also can learn to compensate for small joint encoder offset errors. Finally, we also run qualitative experiments on a real UR5e to demonstrate the feasibility of our algorithm on a physical robotic system with real data. See https://tinyurl.com/4wz3nf86 for code and supplementary material.