 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Whole-Body Human-Robot Haptic Interaction in Social Contexts
Paper and Code
May 26, 2020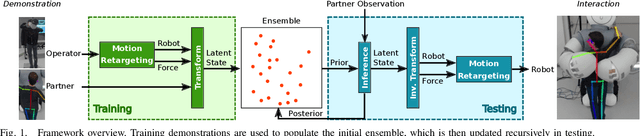
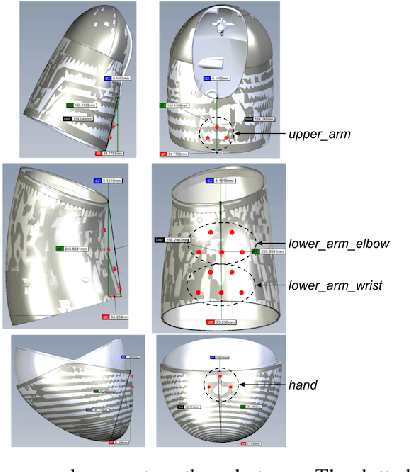
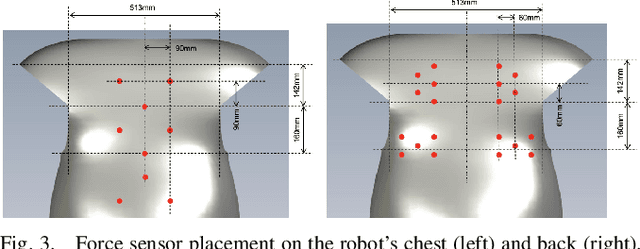
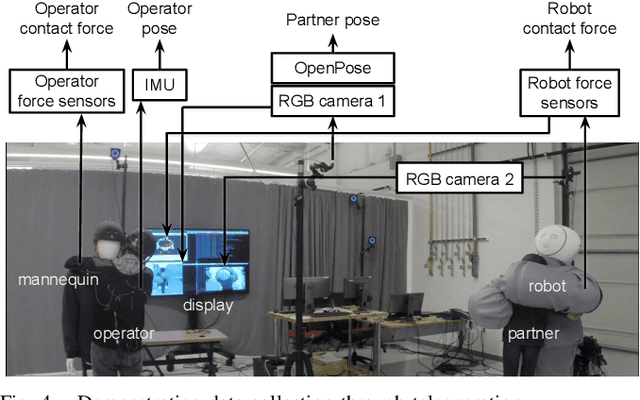
This paper presents a learning-from-demonstration (LfD) framework for teaching human-robot social interactions that involve whole-body haptic interaction, i.e. direct human-robot contact over the full robot body. The performance of existing LfD frameworks suffers in such interactions due to the high dimensionality and spatiotemporal sparsity of the demonstration data. We show that by leveraging this sparsity, we can reduce the data dimensionality without incurring a significant accuracy penalty, and introduce three strategies for doing so. By combining these techniques with an LfD framework for learning multimodal human-robot interactions, we can model the spatiotemporal relationship between the tactile and kinesthetic information during whole-body haptic interactions. Using a teleoperated bimanual robot equipped with 61 force sensors, we experimentally demonstrate that a model trained with 121 sample hugs from 4 participants generalizes well to unseen inputs and human partners.