 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic TMoE: A Drift-Aware Dynamic Mixture of Experts Framework for Non-Stationary Time Series Forecasting
May 20, 2026Non-stationary time series forecasting is challenged by evolving distribution shifts that static models struggle to capture. While Mixture-of-Experts (MoE) architectures offer a promising paradigm for decoupling complex drift patterns, existing approaches are limited by fixed expert pools and memoryless routing, hampering their ability to adapt to abrupt regime shifts. To address this, we propose Dynamic TMoE, a framework that unifies architectural evolution with temporal continuity during learning phase. By detecting distribution shifts via Maximum Mean Discrepancy (MMD), we dynamically instantiate heterogeneous experts and prune redundant ones to optimize capacity. Additionally, a temporal memory router leverages recurrent states and an anomaly repository to ensure stable, context-aware expert selection without requiring test-time updates. Experiments on nine benchmarks demonstrate state-of-the-art performance, reducing MSE by 10.4% and MAE by 7.8%. Code is available at https://github.com/andone-07/Dynamic-TMoE.
HeterCSI: Channel-Adaptive Heterogeneous CSI Pretraining Framework for Generalized Wireless Foundation Models
Jan 26, 2026Wireless foundation models promise transformative capabilities for channel state information (CSI) processing across diverse 6G network applications, yet face fundamental challenges due to the inherent dual heterogeneity of CSI across both scale and scenario dimensions. However, current pretraining approaches either constrain inputs to fixed dimensions or isolate training by scale, limiting the generalization and scalability of wireless foundation models. In this paper, we propose HeterCSI, a channel-adaptive pretraining framework that reconciles training efficiency with robust cross-scenario generalization via a new understanding of gradient dynamics in heterogeneous CSI pretraining. Our key insight reveals that CSI scale heterogeneity primarily causes destructive gradient interference, while scenario diversity actually promotes constructive gradient alignment when properly managed. Specifically, we formulate heterogeneous CSI batch construction as a partitioning optimization problem that minimizes zero-padding overhead while preserving scenario diversity. To solve this, we develop a scale-aware adaptive batching strategy that aligns CSI samples of similar scales, and design a double-masking mechanism to isolate valid signals from padding artifacts. Extensive experiments on 12 datasets demonstrate that HeterCSI establishes a generalized foundation model without scenario-specific finetuning, achieving superior average performance over full-shot baselines. Compared to the state-of-the-art zero-shot benchmark WiFo, it reduces NMSE by 7.19 dB, 4.08 dB, and 5.27 dB for CSI reconstruction, time-domain, and frequency-domain prediction, respectively. The proposed HeterCSI framework also reduces training latency by 53% compared to existing approaches while improving generalization performance by 1.53 dB on average.
Reasoning Efficiently Through Adaptive Chain-of-Thought Compression: A Self-Optimizing Framework
Sep 17, 2025
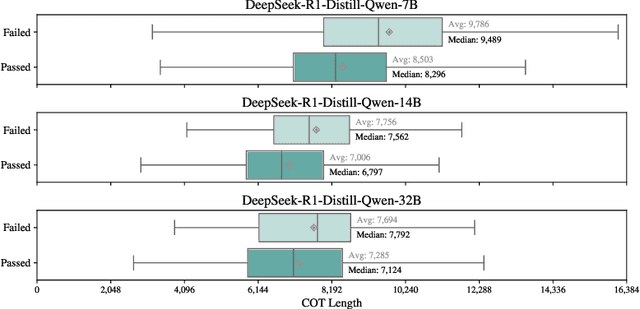
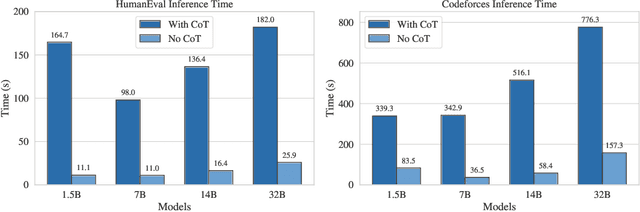
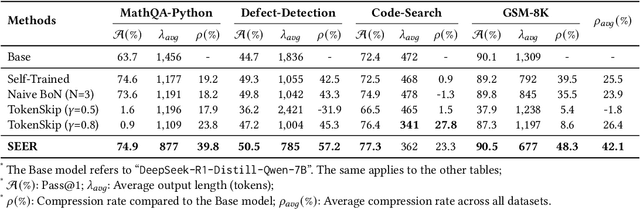
Chain-of-Thought (CoT) reasoning enhances Large Language Models (LLMs) by prompting intermediate steps, improving accuracy and robustness in arithmetic, logic, and commonsense tasks. However, this benefit comes with high computational costs: longer outputs increase latency, memory usage, and KV-cache demands. These issues are especially critical in software engineering tasks where concise and deterministic outputs are required. To investigate these trade-offs, we conduct an empirical study based on code generation benchmarks. The results reveal that longer CoT does not always help. Excessive reasoning often causes truncation, accuracy drops, and latency up to five times higher, with failed outputs consistently longer than successful ones. These findings challenge the assumption that longer reasoning is inherently better and highlight the need for adaptive CoT control. Motivated by this, we propose SEER (Self-Enhancing Efficient Reasoning), an adaptive framework that compresses CoT while preserving accuracy. SEER combines Best-of-N sampling with task-aware adaptive filtering, dynamically adjusting thresholds based on pre-inference outputs to reduce verbosity and computational overhead. We then evaluate SEER on three software engineering tasks and one math task. On average, SEER shortens CoT by 42.1%, improves accuracy by reducing truncation, and eliminates most infinite loops. These results demonstrate SEER as a practical method to make CoT-enhanced LLMs more efficient and robust, even under resource constraints.
A Survey of Deep Graph Learning under Distribution Shifts: from Graph Out-of-Distribution Generalization to Adaptation
Oct 25, 2024Distribution shifts on graphs -- the discrepancies in data distribution between training and employing a graph machine learning model -- are ubiquitous and often unavoidable in real-world scenarios. These shifts may severely deteriorate model performance, posing significant challenges for reliable graph machine learning. Consequently, there has been a surge in research on graph machine learning under distribution shifts, aiming to train models to achieve satisfactory performance on out-of-distribution (OOD) test data. In our survey, we provide an up-to-date and forward-looking review of deep graph learning under distribution shifts. Specifically, we cover three primary scenarios: graph OOD generalization, training-time graph OOD adaptation, and test-time graph OOD adaptation. We begin by formally formulating the problems and discussing various types of distribution shifts that can affect graph learning, such as covariate shifts and concept shifts. To provide a better understanding of the literature, we systematically categorize the existing models based on our proposed taxonomy and investigate the adopted techniques behind. We also summarize commonly used datasets in this research area to facilitate further investigation. Finally, we point out promising research directions and the corresponding challenges to encourage further study in this vital domain. Additionally, we provide a continuously updated reading list at https://github.com/kaize0409/Awesome-Graph-OOD.
Beyond Generalization: A Survey of Out-Of-Distribution Adaptation on Graphs
Feb 17, 2024Distribution shifts on graphs -- the data distribution discrepancies between training and testing a graph machine learning model, are often ubiquitous and unavoidable in real-world scenarios. Such shifts may severely deteriorate the performance of the model, posing significant challenges for reliable graph machine learning. Consequently, there has been a surge in research on graph Out-Of-Distribution (OOD) adaptation methods that aim to mitigate the distribution shifts and adapt the knowledge from one distribution to another. In our survey, we provide an up-to-date and forward-looking review of graph OOD adaptation methods, covering two main problem scenarios including training-time as well as test-time graph OOD adaptation. We start by formally formulating the two problems and then discuss different types of distribution shifts on graphs. Based on our proposed taxonomy for graph OOD adaptation, we systematically categorize the existing methods according to their learning paradigm and investigate the techniques behind them. Finally, we point out promising research directions and the corresponding challenges. We also provide a continuously updated reading list at https://github.com/kaize0409/Awesome-Graph-OOD-Adaptation.git
PlotThread: Creating Expressive Storyline Visualizations using Reinforcement Learning
Sep 01, 2020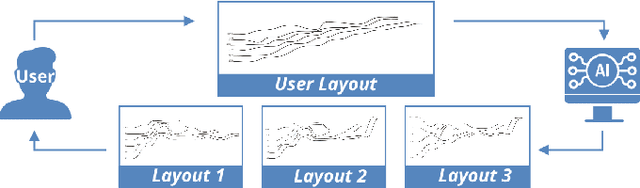
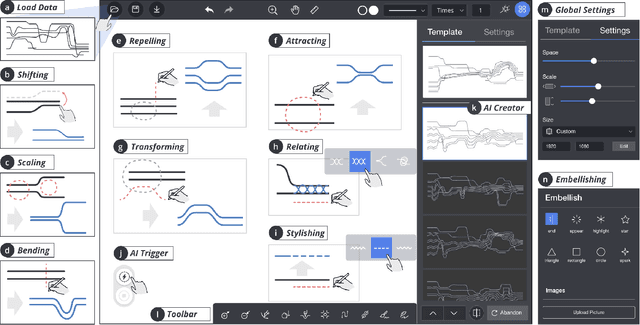
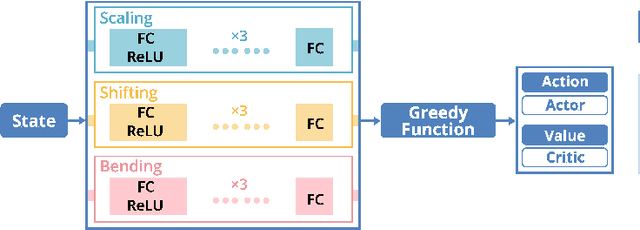
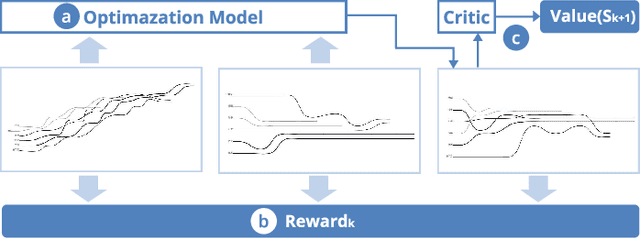
Storyline visualizations are an effective means to present the evolution of plots and reveal the scenic interactions among characters. However, the design of storyline visualizations is a difficult task as users need to balance between aesthetic goals and narrative constraints. Despite that the optimization-based methods have been improved significantly in terms of producing aesthetic and legible layouts, the existing (semi-) automatic methods are still limited regarding 1) efficient exploration of the storyline design space and 2) flexible customization of storyline layouts. In this work, we propose a reinforcement learning framework to train an AI agent that assists users in exploring the design space efficiently and generating well-optimized storylines. Based on the framework, we introduce PlotThread, an authoring tool that integrates a set of flexible interactions to support easy customization of storyline visualizations. To seamlessly integrate the AI agent into the authoring process, we employ a mixed-initiative approach where both the agent and designers work on the same canvas to boost the collaborative design of storylines. We evaluate the reinforcement learning model through qualitative and quantitative experiments and demonstrate the usage of PlotThread using a collection of use cases.