 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Complex Behaviors: Multi-Personality Composition and Dynamic Switching in Vision-Language Models
Jun 09, 2026With the widespread deployment of Multimodal Large Language Models (MLLMs) in social interaction, understanding and controlling their behavior under complex personality conditions is essential. This paper introduces explicit personality conditioning and establishes a systematic evaluation framework encompassing single-personality induction, multi-personality induction, and personality switching. Experiments show that personality induction improves image captioning performance but can impair performance on tasks requiring precise reasoning, such as visual question answering (VQA). Balancing and residual effects are observed during multi-trait composition and dynamic switching, indicating that model behavior is co-modulated by both previous and current personality constraints. Existing prompt-based personality induction methods show limited transferability to multimodal settings. Our work reveals the dynamic and complex nature of personality modeling in MLLMs and underscores the need for robust, tailored methods for personality induction and evaluation. The code will be released when the paper is accepted.
Implicit Identity Technologies for LLMs: Fingerprinting and Watermarking across Datasets, Models, and Generated Content
May 28, 2026This paper presents a survey and taxonomy of LLM fingerprinting and watermarking for identity, ownership verification, provenance, and generated-content attribution. Large language models (LLMs) require substantial investments in data, computation, and expertise, and are increasingly deployed in high-stakes settings, making it critical to protect LLM-related assets and trace their origins. Existing work has rapidly expanded across dataset provenance, model ownership, and generated-content detection, but the field remains fragmented: fingerprinting and watermarking are often used inconsistently, and methods are typically studied within isolated asset-specific settings. To address this gap, we introduce implicit identity as a unifying abstraction for verifiable but not directly observable identity signals in LLM systems. We distinguish fingerprinting as non-intrusive identity derived from intrinsic characteristics, and watermarking as intrusive identity deliberately embedded into data, models, or generated content. We then propose a lifecycle-based taxonomy that organises techniques across datasets, models, and generated content, and further separates them by verification semantics: similarity-based attribution and keyed verification. Finally, we establish an evaluation framework centred on identifiability, robustness, and deployability, summarising representative metrics under realistic access and transformation regimes. By unifying terminology, lifecycle stages, and evaluation objectives, this survey provides a structured foundation for studying LLM identity technologies and for developing more reliable mechanisms for asset protection and provenance.
Security of OpenClaw Agents: Fundamentals, Attacks, and Countermeasures
May 25, 2026The rapid evolution of large language model (LLM)-driven autonomous agents has given rise to OpenClaw, a new class of open-source agent frameworks that operate as continuously running, skill-augmented systems with persistent memory, multi-channel interaction, and high degrees of autonomy. Such capabilities enable OpenClaw agents to autonomously execute complex, multi-step tasks and interact seamlessly with external applications, but simultaneously introduce a substantially enlarged attack surface. In particular, the combination of high-privilege operations and persistent memory exposes OpenClaw agents to various emerging threats, including skill poisoning, cognitive manipulation, multi-agent cascading failures, and supply-chain vulnerabilities. In this survey, we present a comprehensive study of the security landscape of OpenClaw agents. We first examine the general architecture and key characteristics that distinguish OpenClaw agents from traditional AI agent systems. We categorize existing security and privacy threats into a layered framework and analyze how vulnerabilities arise during agent reasoning, action execution, and external interaction. Representative defense mechanisms are also reviewed to draw the current defense landscape. Finally, several unresolved issues related to the reliability and trustworthiness of OpenClaw ecosystems are discussed.
Angel or Demon: Investigating the Plasticity Interventions' Impact on Backdoor Threats in Deep Reinforcement Learning
May 14, 2026Extensive research has highlighted the severe threats posed by backdoor attacks to deep reinforcement learning (DRL). However, prior studies primarily focus on vanilla scenarios, while plasticity interventions have emerged as indispensable built-in components of modern DRL agents. Despite their effectiveness in mitigating plasticity loss, the impact of these interventions on DRL backdoor vulnerabilities remains underexplored, and this lack of systematic investigation poses risks in practical DRL deployments. To bridge this gap, we empirically study 14,664 cases integrating representative interventions and attack scenarios. We find that only one intervention (i.e., SAM) exacerbates backdoor threats, while other interventions mitigate them. Pathological analysis identifies that the exacerbation is attributed to backdoor gradient amplification, while the mitigation stems from activation pathway disruption and representation space compression. From these findings, we derive two novel insights: (1) a conceptual framework SCC for robust backdoor injection that deconstructs the mechanistic interplay between interventions and backdoors in DRL, and (2) abnormal loss landscape sharpness as a key indicator for DRL backdoor detection.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
Enabling Regulatory Multi-Agent Collaboration: Architecture, Challenges, and Solutions
Sep 11, 2025



Large language models (LLMs)-empowered autonomous agents are transforming both digital and physical environments by enabling adaptive, multi-agent collaboration. While these agents offer significant opportunities across domains such as finance, healthcare, and smart manufacturing, their unpredictable behaviors and heterogeneous capabilities pose substantial governance and accountability challenges. In this paper, we propose a blockchain-enabled layered architecture for regulatory agent collaboration, comprising an agent layer, a blockchain data layer, and a regulatory application layer. Within this framework, we design three key modules: (i) an agent behavior tracing and arbitration module for automated accountability, (ii) a dynamic reputation evaluation module for trust assessment in collaborative scenarios, and (iii) a malicious behavior forecasting module for early detection of adversarial activities. Our approach establishes a systematic foundation for trustworthy, resilient, and scalable regulatory mechanisms in large-scale agent ecosystems. Finally, we discuss the future research directions for blockchain-enabled regulatory frameworks in multi-agent systems.
ArtistAuditor: Auditing Artist Style Pirate in Text-to-Image Generation Models
Apr 17, 2025Text-to-image models based on diffusion processes, such as DALL-E, Stable Diffusion, and Midjourney, are capable of transforming texts into detailed images and have widespread applications in art and design. As such, amateur users can easily imitate professional-level paintings by collecting an artist's work and fine-tuning the model, leading to concerns about artworks' copyright infringement. To tackle these issues, previous studies either add visually imperceptible perturbation to the artwork to change its underlying styles (perturbation-based methods) or embed post-training detectable watermarks in the artwork (watermark-based methods). However, when the artwork or the model has been published online, i.e., modification to the original artwork or model retraining is not feasible, these strategies might not be viable. To this end, we propose a novel method for data-use auditing in the text-to-image generation model. The general idea of ArtistAuditor is to identify if a suspicious model has been finetuned using the artworks of specific artists by analyzing the features related to the style. Concretely, ArtistAuditor employs a style extractor to obtain the multi-granularity style representations and treats artworks as samplings of an artist's style. Then, ArtistAuditor queries a trained discriminator to gain the auditing decisions. The experimental results on six combinations of models and datasets show that ArtistAuditor can achieve high AUC values (> 0.937). By studying ArtistAuditor's transferability and core modules, we provide valuable insights into the practical implementation. Finally, we demonstrate the effectiveness of ArtistAuditor in real-world cases by an online platform Scenario. ArtistAuditor is open-sourced at https://github.com/Jozenn/ArtistAuditor.
UNIDOOR: A Universal Framework for Action-Level Backdoor Attacks in Deep Reinforcement Learning
Jan 26, 2025



Deep reinforcement learning (DRL) is widely applied to safety-critical decision-making scenarios. However, DRL is vulnerable to backdoor attacks, especially action-level backdoors, which pose significant threats through precise manipulation and flexible activation, risking outcomes like vehicle collisions or drone crashes. The key distinction of action-level backdoors lies in the utilization of the backdoor reward function to associate triggers with target actions. Nevertheless, existing studies typically rely on backdoor reward functions with fixed values or conditional flipping, which lack universality across diverse DRL tasks and backdoor designs, resulting in fluctuations or even failure in practice. This paper proposes the first universal action-level backdoor attack framework, called UNIDOOR, which enables adaptive exploration of backdoor reward functions through performance monitoring, eliminating the reliance on expert knowledge and grid search. We highlight that action tampering serves as a crucial component of action-level backdoor attacks in continuous action scenarios, as it addresses attack failures caused by low-frequency target actions. Extensive evaluations demonstrate that UNIDOOR significantly enhances the attack performance of action-level backdoors, showcasing its universality across diverse attack scenarios, including single/multiple agents, single/multiple backdoors, discrete/continuous action spaces, and sparse/dense reward signals. Furthermore, visualization results encompassing state distribution, neuron activation, and animations demonstrate the stealthiness of UNIDOOR. The source code of UNIDOOR can be found at https://github.com/maoubo/UNIDOOR.
Movable Antennas Enabled ISAC Systems: Fundamentals, Opportunities, and Future Directions
Dec 30, 2024The movable antenna (MA)-enabled integrated sensing and communication (ISAC) system attracts widespread attention as an innovative framework. The ISAC system integrates sensing and communication functions, achieving resource sharing across various domains, significantly enhancing communication and sensing performance, and promoting the intelligent interconnection of everything. Meanwhile, MA utilizes the spatial variations of wireless channels by dynamically adjusting the positions of MA elements at the transmitter and receiver to improve the channel and further enhance the performance of the ISAC systems. In this paper, we first outline the fundamental principles of MA and introduce the application scenarios of MA-enabled ISAC systems. Then, we summarize the advantages of MA-enabled ISAC systems in enhancing spectral efficiency, achieving flexible and precise beamforming, and making the signal coverage range adjustable. Besides, a specific case is studied to show the performance gains in terms of transmit power that MA brings to ISAC systems. Finally, we discuss the challenges of MA-enabled ISAC and future research directions, aiming to provide insights for future research on MA-enabled ISAC systems.
SoK: Dataset Copyright Auditing in Machine Learning Systems
Oct 22, 2024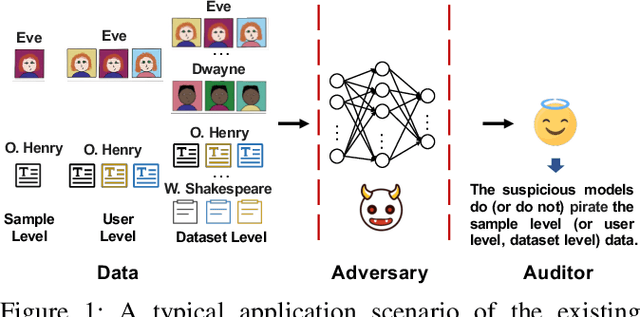
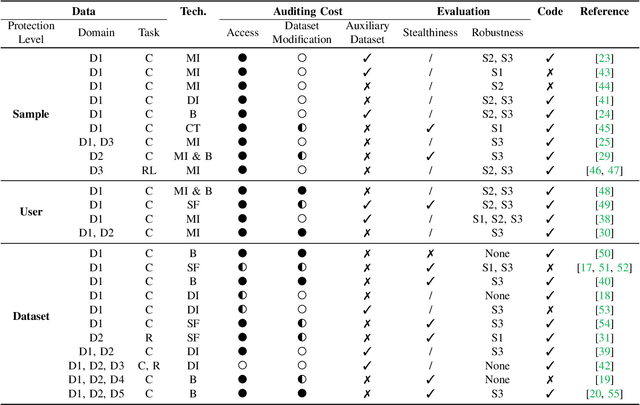
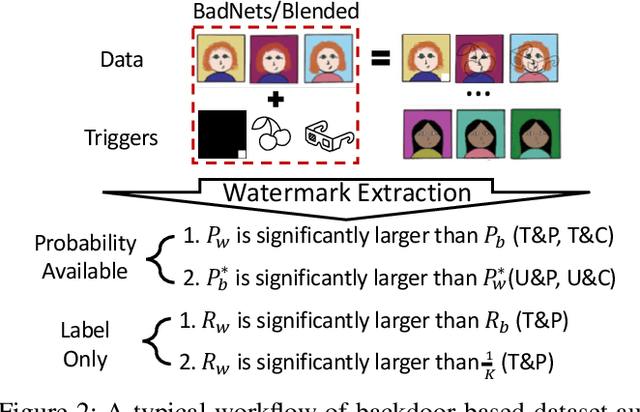

As the implementation of machine learning (ML) systems becomes more widespread, especially with the introduction of larger ML models, we perceive a spring demand for massive data. However, it inevitably causes infringement and misuse problems with the data, such as using unauthorized online artworks or face images to train ML models. To address this problem, many efforts have been made to audit the copyright of the model training dataset. However, existing solutions vary in auditing assumptions and capabilities, making it difficult to compare their strengths and weaknesses. In addition, robustness evaluations usually consider only part of the ML pipeline and hardly reflect the performance of algorithms in real-world ML applications. Thus, it is essential to take a practical deployment perspective on the current dataset copyright auditing tools, examining their effectiveness and limitations. Concretely, we categorize dataset copyright auditing research into two prominent strands: intrusive methods and non-intrusive methods, depending on whether they require modifications to the original dataset. Then, we break down the intrusive methods into different watermark injection options and examine the non-intrusive methods using various fingerprints. To summarize our results, we offer detailed reference tables, highlight key points, and pinpoint unresolved issues in the current literature. By combining the pipeline in ML systems and analyzing previous studies, we highlight several future directions to make auditing tools more suitable for real-world copyright protection requirements.