 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-preserving Distributed Machine Learning via Local Randomization and ADMM Perturbation
Paper and Code
Sep 09, 2019
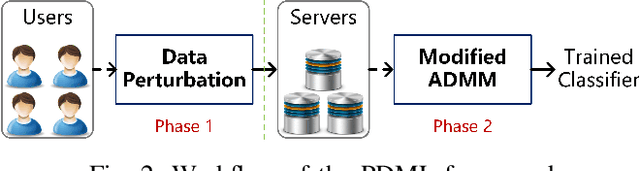
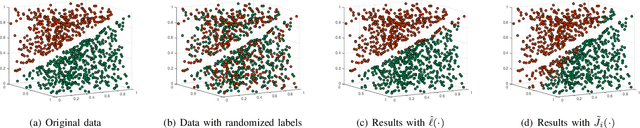
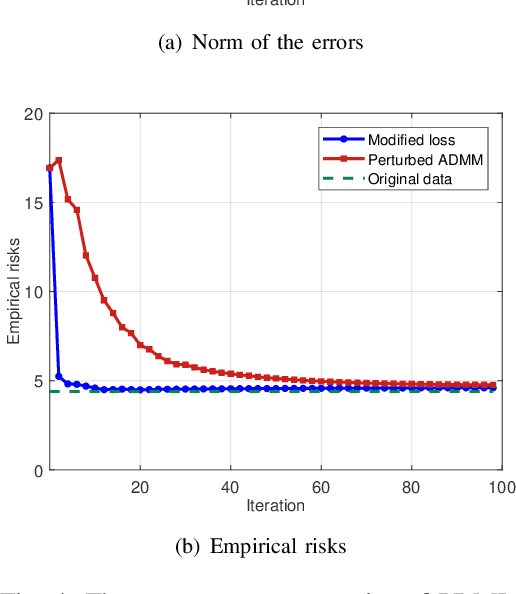
With the proliferation of training data, distributed machine learning (DML) is becoming more competent for large-scale learning tasks. However, privacy concerns have to be given priority in DML, since training data may contain sensitive information of users. In this paper, we propose a privacy-preserving ADMM-based DML framework with two novel features: First, we remove the assumption commonly made in the literature that the users trust the server collecting their data. Second, the framework provides heterogeneous privacy for users depending on data's sensitive levels and servers' trust degrees. The challenging issue is to keep the accumulation of privacy losses over ADMM iterations minimal. In the proposed framework, a local randomization approach, which is differentially private, is adopted to provide users with self-controlled privacy guarantee for the most sensitive information. Further, the ADMM algorithm is perturbed through a combined noise-adding method, which simultaneously preserves privacy for users' less sensitive information and strengthens the privacy protection of the most sensitive information. We provide detailed analyses on the performance of the trained model according to its generalization error. Finally, we conduct extensive experiments using real-world datasets to validate the theoretical results and evaluate the classification performance of the proposed framework.