 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel to Gaussian: Ultra-Fast Continuous Super-Resolution with 2D Gaussian Modeling
Mar 09, 2025Arbitrary-scale super-resolution (ASSR) aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs with arbitrary upsampling factors using a single model, addressing the limitations of traditional SR methods constrained to fixed-scale factors (\textit{e.g.}, $\times$ 2). Recent advances leveraging implicit neural representation (INR) have achieved great progress by modeling coordinate-to-pixel mappings. However, the efficiency of these methods may suffer from repeated upsampling and decoding, while their reconstruction fidelity and quality are constrained by the intrinsic representational limitations of coordinate-based functions. To address these challenges, we propose a novel ContinuousSR framework with a Pixel-to-Gaussian paradigm, which explicitly reconstructs 2D continuous HR signals from LR images using Gaussian Splatting. This approach eliminates the need for time-consuming upsampling and decoding, enabling extremely fast arbitrary-scale super-resolution. Once the Gaussian field is built in a single pass, ContinuousSR can perform arbitrary-scale rendering in just 1ms per scale. Our method introduces several key innovations. Through statistical ana
DCQA: Document-Level Chart Question Answering towards Complex Reasoning and Common-Sense Understanding
Oct 29, 2023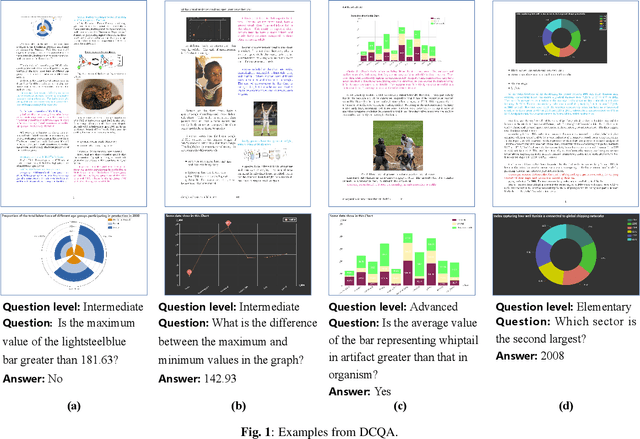
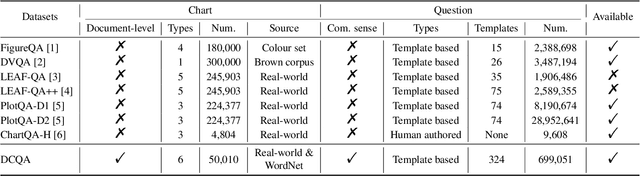
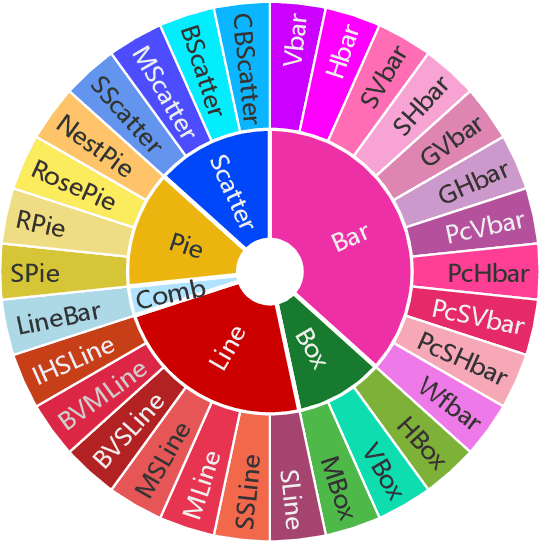

Visually-situated languages such as charts and plots are omnipresent in real-world documents. These graphical depictions are human-readable and are often analyzed in visually-rich documents to address a variety of questions that necessitate complex reasoning and common-sense responses. Despite the growing number of datasets that aim to answer questions over charts, most only address this task in isolation, without considering the broader context of document-level question answering. Moreover, such datasets lack adequate common-sense reasoning information in their questions. In this work, we introduce a novel task named document-level chart question answering (DCQA). The goal of this task is to conduct document-level question answering, extracting charts or plots in the document via document layout analysis (DLA) first and subsequently performing chart question answering (CQA). The newly developed benchmark dataset comprises 50,010 synthetic documents integrating charts in a wide range of styles (6 styles in contrast to 3 for PlotQA and ChartQA) and includes 699,051 questions that demand a high degree of reasoning ability and common-sense understanding. Besides, we present the development of a potent question-answer generation engine that employs table data, a rich color set, and basic question templates to produce a vast array of reasoning question-answer pairs automatically. Based on DCQA, we devise an OCR-free transformer for document-level chart-oriented understanding, capable of DLA and answering complex reasoning and common-sense questions over charts in an OCR-free manner. Our DCQA dataset is expected to foster research on understanding visualizations in documents, especially for scenarios that require complex reasoning for charts in the visually-rich document. We implement and evaluate a set of baselines, and our proposed method achieves comparable results.
Progressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023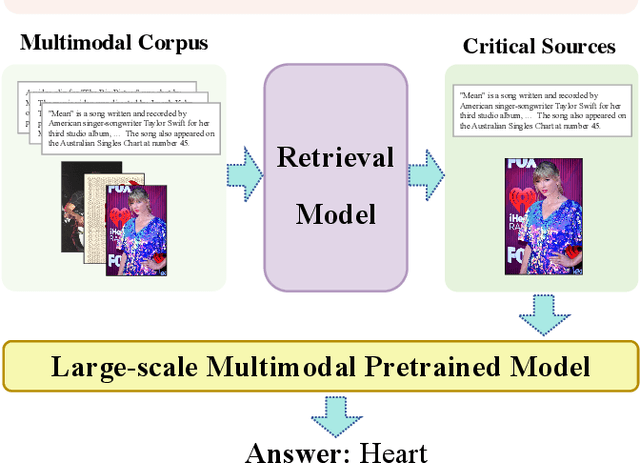

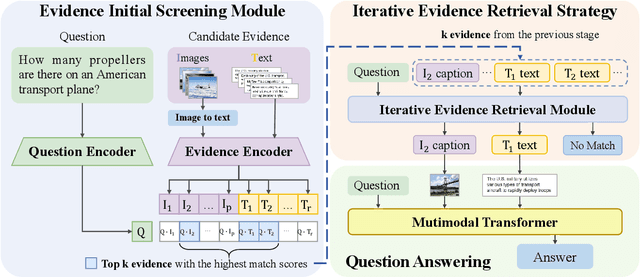
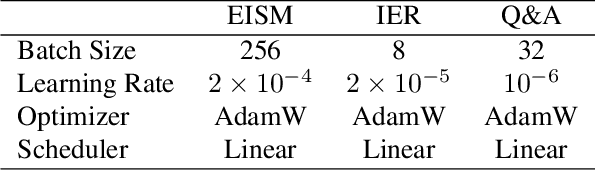
Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.