 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Restoration for Multi-Modal 3D Object Detection in Adverse Weather
Dec 18, 2025Multi-modal 3D object detection is important for reliable perception in robotics and autonomous driving. However, its effectiveness remains limited under adverse weather conditions due to weather-induced distortions and misalignment between different data modalities. In this work, we propose DiffFusion, a novel framework designed to enhance robustness in challenging weather through diffusion-based restoration and adaptive cross-modal fusion. Our key insight is that diffusion models possess strong capabilities for denoising and generating data that can adapt to various weather conditions. Building on this, DiffFusion introduces Diffusion-IR restoring images degraded by weather effects and Point Cloud Restoration (PCR) compensating for corrupted LiDAR data using image object cues. To tackle misalignments between two modalities, we develop Bidirectional Adaptive Fusion and Alignment Module (BAFAM). It enables dynamic multi-modal fusion and bidirectional bird's-eye view (BEV) alignment to maintain consistent spatial correspondence. Extensive experiments on three public datasets show that DiffFusion achieves state-of-the-art robustness under adverse weather while preserving strong clean-data performance. Zero-shot results on the real-world DENSE dataset further validate its generalization. The implementation of our DiffFusion will be released as open-source.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Active Stacking for Heart Rate Estimation
Mar 26, 2019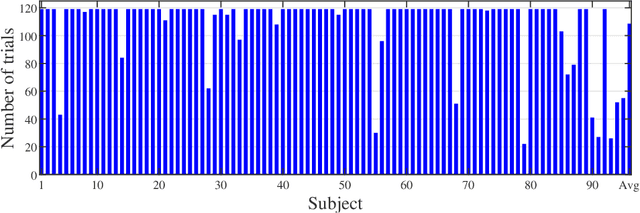
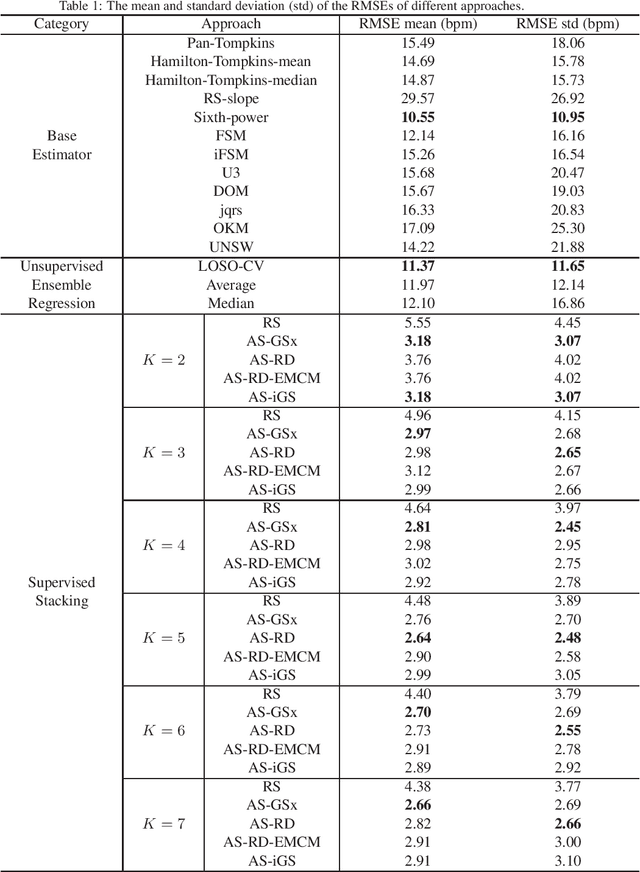
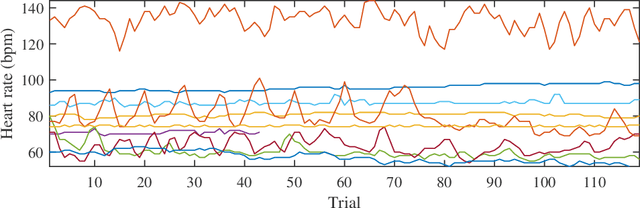
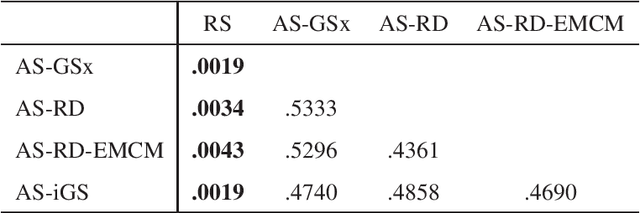
Heart rate estimation from electrocardiogram signals is very important for the early detection of cardiovascular diseases. However, due to large individual differences and varying electrocardiogram signal quality, there does not exist a single reliable estimation algorithm that works well on all subjects. Every algorithm may break down on certain subjects, resulting in a significant estimation error. Ensemble regression, which aggregates the outputs of multiple base estimators for more reliable and stable estimates, can be used to remedy this problem. Moreover, active learning can be used to optimally select a few trials from a new subject to label, based on which a stacking ensemble regression model can be trained to aggregate the base estimators. This paper proposes four active stacking approaches, and demonstrates that they all significantly outperform three common unsupervised ensemble regression approaches, and a supervised stacking approach which randomly selects some trials to label. Remarkably, our active stacking approaches only need three or four labeled trials from each subject to achieve an average root mean squared estimation error below three beats per minute, making them very convenient for real-world applications. To our knowledge, this is the first research on active stacking, and its application to heart rate estimation.