 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject Envelope based Multitype Reconstruction Algorithm of Speech Samples of Parkinson's Disease
Aug 23, 2021
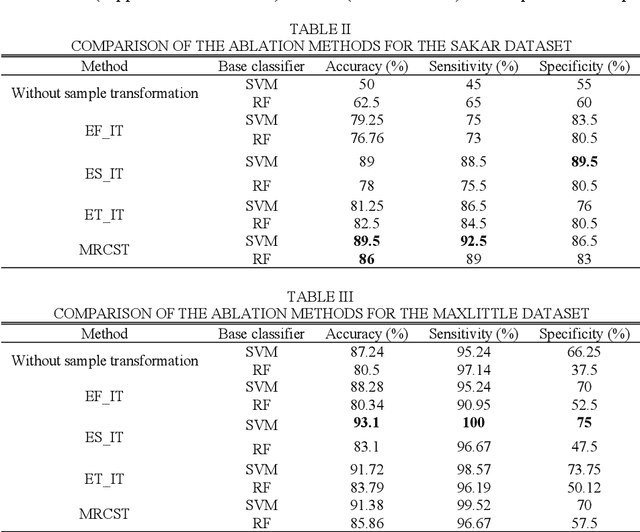

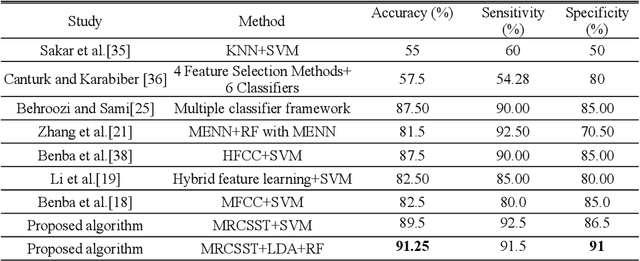
The risk of Parkinson's disease (PD) is extremely serious, and PD speech recognition is an effective method of diagnosis nowadays. However, due to the influence of the disease stage, corpus, and other factors on data collection, the ability of every samples within one subject to reflect the status of PD vary. No samples are useless totally, and not samples are 100% perfect. This characteristic means that it is not suitable just to remove some samples or keep some samples. It is necessary to consider the sample transformation for obtaining high quality new samples. Unfortunately, existing PD speech recognition methods focus mainly on feature learning and classifier design rather than sample learning, and few methods consider the sample transformation. To solve the problem above, a PD speech sample transformation algorithm based on multitype reconstruction operators is proposed in this paper. The algorithm is divided into four major steps. Three types of reconstruction operators are designed in the algorithm: types A, B and C. Concerning the type A operator, the original dataset is directly reconstructed by designing a linear transformation to obtain the first dataset. The type B operator is designed for clustering and linear transformation of the dataset to obtain the second new dataset. The third operator, namely, the type C operator, reconstructs the dataset by clustering and convolution to obtain the third dataset. Finally, the base classifier is trained based on the three new datasets, and then the classification results are fused by decision weighting. In the experimental section, two representative PD speech datasets are used for verification. The results show that the proposed algorithm is effective. Compared with other algorithms, the proposed algorithm achieves apparent improvements in terms of classification accuracy.