 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Ordinal Factorization Model: Deciphering the Effects of Attributes by Piece-wise Linear Approximation
Nov 14, 2019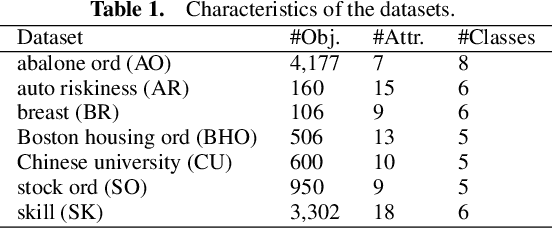
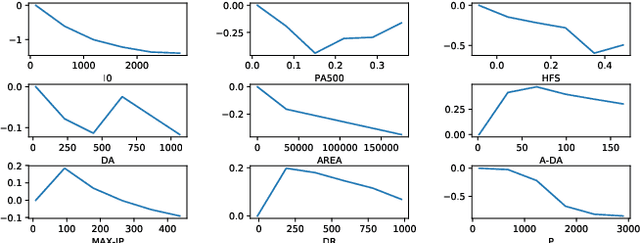

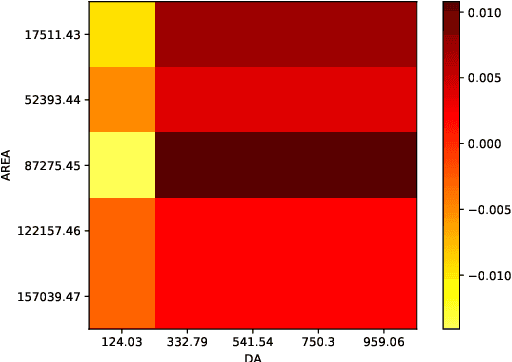
Ordinal regression predicts the objects' labels that exhibit a natural ordering, which is important to many managerial problems such as credit scoring and clinical diagnosis. In these problems, the ability to explain how the attributes affect the prediction is critical to users. However, most, if not all, existing ordinal regression models simplify such explanation in the form of constant coefficients for the main and interaction effects of individual attributes. Such explanation cannot characterize the contributions of attributes at different value scales. To address this challenge, we propose a new explainable ordinal regression model, namely, the Explainable Ordinal Factorization Model (XOFM). XOFM uses the piece-wise linear functions to approximate the actual contributions of individual attributes and their interactions. Moreover, XOFM introduces a novel ordinal transformation process to assign each object the probabilities of belonging to multiple relevant classes, instead of fixing boundaries to differentiate classes. XOFM is based on the Factorization Machines to handle the potential sparsity problem as a result of discretizing the attribute scales. Comprehensive experiments with benchmark datasets and baseline models demonstrate that the proposed XOFM exhibits superior explainability and leads to state-of-the-art prediction accuracy.